Was ist ein Branch?
Um wirklich zu verstehen wie Git Branching durchführt, müssen wir einen Schritt zurück gehen und untersuchen wie Git die Daten speichert. Wie du dich vielleicht noch an Kapitel 1 erinnerst, speichert Git seine Daten nicht als Serie von Änderungen oder Unterschieden, sondern als Serie von Schnappschüssen.
Wenn du in Git committest, speichert Git ein sogenanntes Commit-Objekt. Dieses enthält einen Zeiger zu dem Schnappschuss mit den Objekten der Staging-Area, dem Autor, den Commit-Metadaten und einem Zeiger zu den direkten Eltern des Commits. Ein initialer Commit hat keine Eltern-Commits, ein normaler Commit stammt von einem Eltern-Commit ab und ein Merge-Commit, welcher aus einer Zussammenführung von zwei oder mehr Branches resultiert, besitzt stammt von ebenso vielen Eltern-Commits ab.
Um das zu verdeutlichen, lass uns annehmen, du hast ein Verzeichnis mit drei Dateien, die du alle zu der Staging-Area hinzufügst und in einem Commit verpackst. Durch das “Stagen” der Dateien erzeugt Git für jede Datei eine Prüfsumme (der SHA-1 Hash, den wir in Kapitel 1 erwähnt haben), speichert diese Version der Datei im Git-Repository (Git referenziert auf diese als Blobs) und fügt die Prüfsumme der Staging-Area hinzu:
$ git add README test.rb LICENSE2
$ git commit -m 'initial commit of my project'Wenn du einen Commit mit dem Kommando git commit erstellst, erzeugt Git für jedes Unterverzeichnis eine Pürfsumme (in diesem Fall nur für das Root-Verzeichnis) und speichert diese drei Objekte im Git Repository. Git erzeugt dann ein Commit Objekt, das die Metadaten und den Pointer zur Wurzel des Projektbaums, um bei Bedarf den Snapshot erneut erzeugen zu können.
Dein Git-Repository enthält nun fünf Objekte: einen Blob für den Inhalt jeder der drei Dateien, einen Baum, der den Inhalt des Verzeichnisses auflistet und spezifiziert welcher Dateiname zu welchem Blob gehört, sowie einen Pointer, der auf die Wurzel des Projektbaumes und die Metadaten des Commits verweist. Prinzipiell können deine Daten im Git Repository wie in Abbildung 3-1 aussehen.
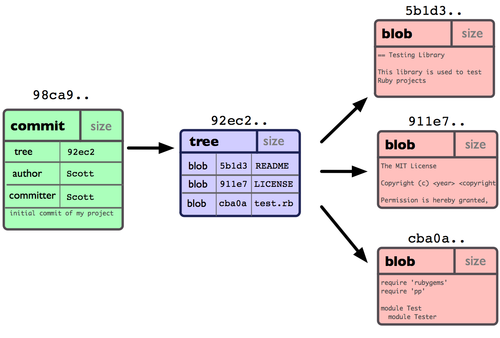
Abbildung 3-1. Repository-Daten eines einzelnen Commits
Wenn du erneut etwas änderst und wieder einen Commit machst, wird dieses einen Zeiger speichern, der auf den Vorhergehenden verweist. Nach zwei weiteren Commits könnte die Historie wie in Abbildung 3-2 aussehen.
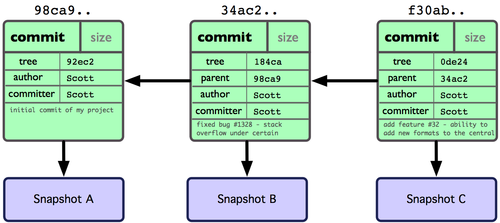
Abbildung 3-2. Git Objektdaten für mehrere Commits
Eine Branch in Git ist nichts anderes als ein simpler Zeiger auf einen dieser Commits. Der Standardname eines Git-Branches lautet master. Mit dem initialen Commit erhältst du einen master-Branch, der auf deinen letzten Commit zeigt. Mit jedem Commit wird bewegt er sich automatisch vorwärts.
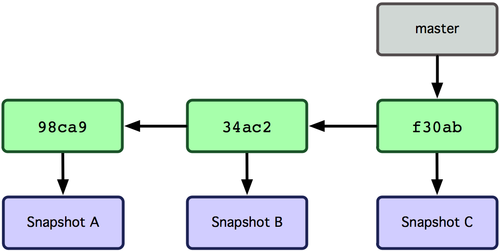
Abbildung 3-3. Branch-Pointer in den Commit-Verlauf
Was passiert, wenn du einen neuen Branch erstellst? Nun, zunächst wird ein neuer Zeiger erstellt. Sagen wir, du erstellst einen neuen Branch mit dem Namen testing. Das machst du mit dem git branch Befehl:
$ git branch testingDies erzeugt einen neuen Pointer auf den gleichen Commit, auf dem du gerade arbeitest (Abbildung 3-4).
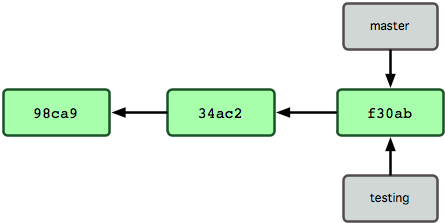
Abbildung 3-4. Mehrere Branches zeigen in den Commit-Verlauf
Woher weiß Git, welche Branch du momentan verwendest? Dafür gibt es einen speziellen Zeiger mit dem Namen “HEAD”. Berücksichtige, dass dieses Konzept sich grundsätzlich von anderen HEAD-Konzepten anderer VCS, wie Subversion oder CVS, unterscheidet. Bei Git handelt es sich um einen Zeiger deines aktuellen lokalen Branches. In dem Fall bist du immer noch auf der master-Branch. Das git branch Kommando hat nur einen neuen Branch erstellt, aber nicht zu diesem gewechselt (Abbildung 3-5).
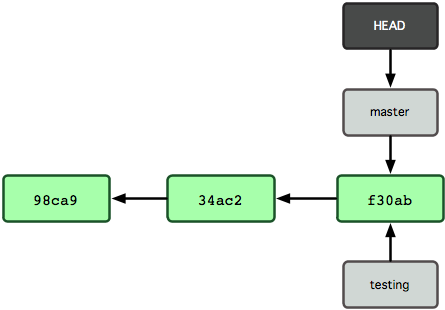
Abbildung 3-5. Der HEAD-Zeiger verweist auf deinen aktuellen Branch
Um zu einem anderen Branch zu wechseln, benutze das Kommando git checkout. Lass uns nun zu unserem neuen testing-Branch wechseln:
$ git checkout testingDas lässt HEAD neuerdings auf den “testing”-Branch verweisen (siehe auch Abbildung 3-6). This moves HEAD to point to the testing branch (see Figure 3-6).
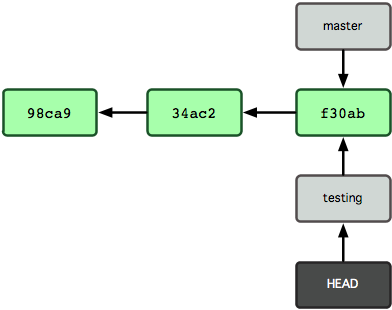
Abbildung 3-6. Wenn du den Branch wechselst, zeigt HEAD auf einen neuen Zweig.
Und was bedeutet das? Ok, lass uns noch einen weiteren Commit machen:
$ vim test.rb
$ git commit -a -m 'made a change'Abbildung 3-7 verdeutlich das Ergebnis.
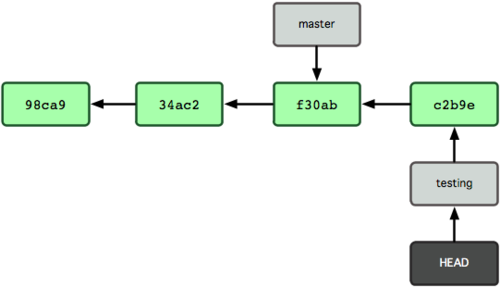
Abbildung 3-7. Der HEAD-Zeiger schreitet mit jedem weiteren Commit voran.
Das ist interessant, denn dein testing-Branch hat sich jetzt voranbewegt und der master-Branch zeigt immernoch auf seinen letzten Commit. Den Commit, den du zuletzt bearbeitet hattest, bevor du mit git checkout den aktuellen Zweig gewechselt hast. Lass uns zurück zu dem master-Branch wechseln:
$ git checkout masterAbbildung 3-8 zeigt das Ergebnis.
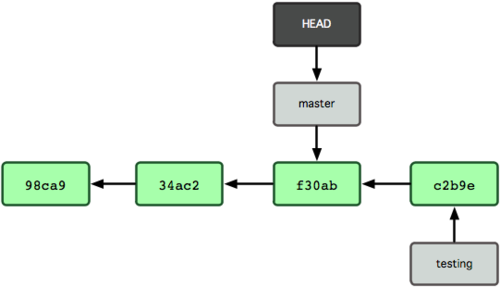
Abbildung 3-8. HEAD bewegt sich nach einem “checkout” zu einem anderen Branch.
Das Kommando zwei Dinge veranlasst. Zum Einen bewegt es den HEAD-Zeiger zurück zum master-Branch, zum Anderen setzt es alle Dateien im Arbeitsverzeichnis auf den Bearbeitungsstand des letzte Commits in diesem Zweig zurück. Das bedeutet aber auch, dass nun alle Änderungen am Projekt vollkommen unabhängig von älteren Projekt-Versionen erfolgen. Kurz gesagt werden alle Änderungen aus dem testing-Zweig vorübergehend rückgängig gemacht und du hast die Möglichkeit einen vollkommen neuen Weg in der Entwicklung einzuschlagen.
Lass uns ein paar Änderungen machen und mit einem Commit festhalten:
$ vim test.rb
$ git commit -a -m 'made other changes'Nun verzweigen sich die Projektverläufe (siehe Abbildung 3-9). Du hast einen Branch erstellt und zu ihm gewechselt, ein bisschen gearbeitet, bist zum zu deinem Haupt-Zweig zurückgekehrt und hast da was ganz anderes gemacht. Beide Arbeiten existieren vollständig unabhängig voneinander in zwei unterschiedlichen Branches. Du kannst beliebig zwischen den beiden Zweigen wechseln und sie zusammenführen, wenn du meinst es wäre soweit. Und das alles hast du mit simplen branch und checkout-Befehlen vollbracht.
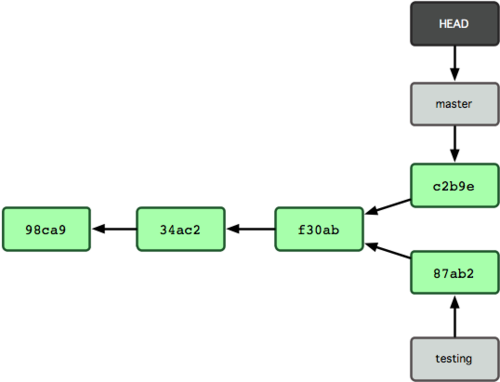
Abbildung 3-9. Die Branch-Historie läuft auseinander.
Eine Branch in Git ist eine einfache Datei, die nur die 40 Zeichen lange SHA-1 Prüfsumme des Commits enthält, auf das sie zeigt. Es kostet nicht viel, Branches zu erstellen und zu zerstören. Das Erstellen einer Branch ist der einfache und schnelle Weg, 41 Bytes in eine Datei zu schreiben (40 Zeichen für die Prüdsumme und ein Zeilenumbruch).
Branches können in Git spielend erstellt und entfernt werden, da sie nur kleine Dateien sind, die eine 40 Zeichen lange SHA-1 Prüfsumme der Commits enthalten, auf die sie verweisen. Einen neuen Zweig zu erstellen erzeugt ebenso viel Aufwand wie das Schreiben einer 41 Byte großen Datei (40 Zeichen und einen Zeilenumbruch).
Das steht im krassen Gegensatz zu dem Weg, den die meisten andere VCS Tools beim Thema Branching einschlagen. Diese kopieren oftmals jeden neuen Entwicklungszweig in ein weiteres Verzeichnis, was - je nach Projektgröße - mehrere Minuten in Anspruch nehmen kann, wohingegen Git diese Aufgabe sofort erledigt. Da wir ausserdem immer den Ursprungs-Commit aufzeichnen, lässt sich problemlos eine gemeinsame Basis für eine Zusammenführung finden und umsetzen. Diese Eigenschaft soll Entwickler ermutigen Entwicklungszweige häufig zu erstellen und zu nutzen.
Lass uns mal sehen, warum du das machen solltest.