Basi di Git
Quindi, cos’è Git in poche parole? Questa è una sezione importante da assorbire, perché se si comprende che cosa è Git e gli elementi fondamentali di come funziona, allora probabilmente, sarà molto più facile per te usare Git efficacemente. Mentre impari Git, cerca di liberare la mente dalle cose che eventualmente conosci su altri VCS, come Subversion e Perforce; ciò ti aiuterà ad evitare di far confusione utilizzando lo strumento. Git immagazzina e tratta le informazioni in modo diverso dagli altri sistemi, anche se l’interfaccia utente è abbastanza simile; comprendere queste differenze aiuta a prevenire di sentirsi confusi, mentre lo si usa.
Snapshot, non Differenze
La principale differenza tra Git e gli altri VCS (Subversion e compagnia), è il modo in cui Git considera i suoi dati. Concettualmente, la maggior parte degli altri sistemi salvano l’informazione come una lista di cambiamenti apportati ai file. Questi sistemi (CVS, Subversion, Perforce, Bazaar e così via), considerano le informazioni che essi mantengono come un insieme di file, con le relative modifiche fatte ai file, nel tempo, come illustrato in Figura 1-4.
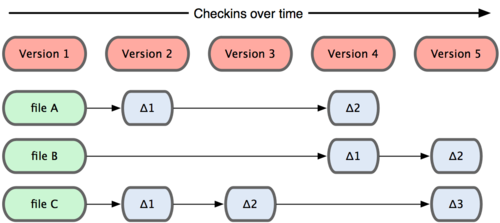
Figura 1-4. Gli altri sistemi tendono ad immagazzinare i dati come cambiamenti alla versione base di ogni file.
Git non considera i dati in questo modo né li immagazzina in questo modo. Invece, Git considera i propri dati più come una serie di istantanee (snapshot) di un mini filesystem. Ogni volta che si fa un commit, o si salva lo stato del proprio progetto in Git, esso fondamentalmente fa un’immagine di tutti i file in quel momento, salvando un riferimento allo snapshot. Per essere efficiente, se alcuni file non sono cambiati, Git non li immagazzina nuovamente — semplicemente crea un collegamento agli stessi file, già immagazzinati, della versione precedente. Git considera i propri dati più come in Figura 1-5.
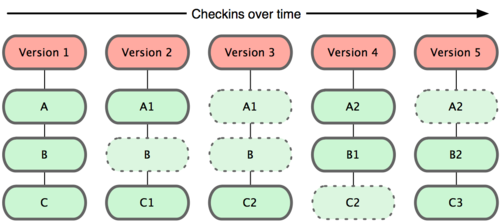
Figura 1-5. Git immagazzina i dati come snapshot del progetto nel tempo.
Questa è una distinzione importante tra Git e gli altri VCS. Git riconsidera tutti gli aspetti del controllo di versione mentre la maggior parte degli altri sistemi copiano dalle precedenti generazioni. Questo fa di Git più un qualche cosa di simile ad un mini filesystem con alcuni incredibili e potenti strumenti costruiti su di esso, invece che un semplice VCS. Esploreremo alcuni benefici che potrai avere immaginando i tuoi dati in questo modo quando vedremo il branching (le ramificazioni) con Git nel Capitolo 3.
Quasi tutte le operazioni sono locali
La maggior parte delle operazioni in Git, necessitano solo di file e risorse locali per operare — generalmente non occorrono informazioni da altri computer nella rete. Se si era abituati ad un CVCS, in cui la maggior parte delle operazioni erano soggette alle latenze di rete, questo aspetto di Git vi farà pensare che gli dei della velocità abbiano benedetto Git con poteri soprannaturali. Giacché l’intera storia del progetto sta qui, sul proprio disco locale, le operazioni sembrano quasi istantanee.
Per esempio, per scorrere la storia di un progetto, Git non ha bisogno di connettersi al server per scaricarla e per poi visualizzarla — la legge direttamente dal database locale. Questo significa che puoi vedere la storia del progetto quasi istantaneamente. Se vuoi vedere i cambiamenti introdotti tra la versione corrente di un file e la versione di un mese fa, Git può consultare il file di un mese fa e calcolare localmente le differenze, invece di richiedere di farlo ad un server remoto o di estrarre una precedente versione del file dal server remoto, per poi farlo in locale.
Questo significa anche che sono minime le cose che non si possono fare se si è offline o non connesso alla VPN. Se sei in aereo o sul treno e vuoi fare un po’ di lavoro, puoi eseguire tranquillamente il commit, anche se non sei connesso alla rete per fare l’upload. Se tornando a casa, trovi che il tuo client VPN non funziona correttamente, puoi comunque lavorare. In molti altri sistemi, fare questo è quasi impossibile o penoso. Con Perforce, per esempio, puoi fare ben poco se non sei connesso al server; e con Subversion e CVS, puoi modificare i file, ma non puoi inviare i cambiamenti al tuo database (perché il database è offline). Tutto ciò non ti può sembrare una gran cosa, tuttavia potresti rimanere di stucco dalla differenza che Git può fare.
Git ha Integrità
Qualsiasi cosa in Git è controllata, tramite checksum, prima di essere salvata ed è referenziata da un checksum. Questo significa che è impossibile cambiare il contenuto di qualsiasi file o directory senza che Git lo sappia. Questa è una funzionalità interna di Git al più basso livello ed è intrinseco nella sua filosofia. Non puoi perdere informazioni nel transito o avere corruzioni di file senza che Git non sia in grado di accorgersene.
Il meccanismo che Git usa per fare questo checksum, è un hash, denominato SHA-1. Si tratta di una stringa di 40-caratteri, composta da caratteri esadecimali (0–9 ed a–f) e calcolata in base al contenuto di file o della struttura di directory in Git. Un hash SHA-1 assomiglia a qualcosa come:
24b9da6552252987aa493b52f8696cd6d3b00373in Git, questi valori di hash si vedono dappertutto, perché Git li usa tantissimo. Infatti, Git immagazzina ogni cosa, nel proprio database indirizzabile, non per nome di file, ma per il valore di hash del suo contenuto.
Git generalmente aggiunge solo dati
Quando si fanno delle azioni in Git, quasi tutte aggiungono solo dati al database di Git. E’ piuttosto difficile che si porti il sistema a fare qualcosa che non sia annullabile o a cancellare i dati in una qualche maniera. Come in altri VCS, si possono perdere o confondere le modifiche, di cui non si è ancora fatto il commit; ma dopo aver fatto il commit di uno snapshot in Git, è veramente difficile perderle, specialmente se si esegue regolarmente, il push del proprio database sull’altro repository.
Questo rende l’uso di Git un piacere perché sappiamo che possiamo sperimentare senza il pericolo di perdere seriamente le cose. Per un maggior approfondimento su come Git salva i dati e come puoi recuperare i dati che sembrano persi, vedi “Sotto il Cofano” nel Capitolo 9.
I tre stati
Ora, prestare attenzione. Questa è la prima cosa da ricordare su Git se si vuole affrontare al meglio il processo di apprendimento. Git ha tre stati principali, in cui possono risiedere i file: committed, modified e staged. Committed significa che il file è immagazzinato al sicuro, nel database locale. Modified significa che il file è stato modificato, ma non è stato ancora eseguito il commit nel proprio database. Staged significa che un file modificato nella versione corrente, è stato contrassegnato per essere inserito nello snapshot, al commit successivo.
Questo ci conduce alle tre sezioni principali di un progetto Git: la directory di Git, la directory di lavoro e l’area di stage.
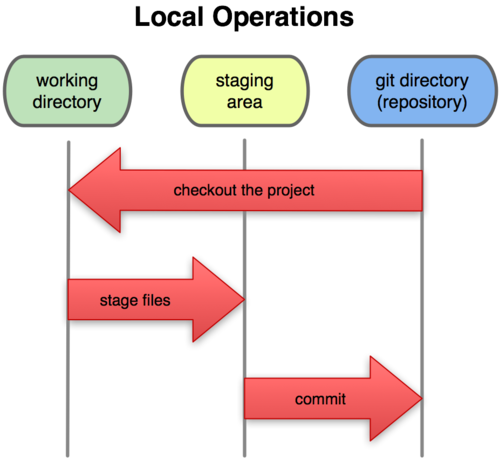
Figura 1-6. Directory di lavoro, area di stage e directory di Git.
La directory di Git è il luogo dove Git salva i metadati ed il database degli oggetti di un progetto. Questa è la parte più importante di Git, ed è ciò che viene copiato quando si clona un repository da un altro computer.
La directory di lavoro è un singolo checkout di una versione del progetto. Questi file sono estratti dal database compresso, nella directory di Git, e posizionati nel disco per essere usati o modificati.
L’area di stage è un semplice file, generalmente contenuto nella directory di Git, contenente le informazioni riguardanti il commit successivo. Qualche volta viene indicato come l’indice, ma sta diventando d’uso comune riferirsi ad essa, come all’area di stage (sosta).
Il flusso base di lavoro in Git, scorre come segue:
- Modificare i file nella directory di lavoro
- Eseguire l’operazione di stage dei file, per aggiungere i relativi snapshot all’area di stage
- Eseguire il commit, per immagazzinare permanentemente nella directory di Git, lo snapshot relativo, una volta presi i file nell’area di stage
Se una versione particolare di un file è nella directory git, sarà considerata committed (già affidata/inviata). Se il file è stato modificato ma è stato aggiunta all’area di staging, è in sosta. E se è stato modificato da quando è stata controllato ma non è stato messo in sosta, sarà modificato. Nel Capitolo 2, imparerai di più su questi stati e come trarne vantaggio da essi o saltare interamente la parte di staging.