Registrare i cambiamenti al repository
In buona fede hai copiato un repository Git e hai la copia di lavoro dei file di questo progetto. Ora puoi apportare alcune modifiche ed inviare gli snapshots di questi cambiamenti nel tuo repository ogni volta che il progetto raggiunge uno stato che vuoi registrare.
Ricorda che ogni file nella tua directory di lavoro è in una dei due stati seguenti: tracciato o non tracciato. I file tracciati sono i file presenti nell’ultimo snapshot; possono essere non modificati, modificati o parcheggiati (stage). I file non tracciati sono tutti gli altri - qualsiasi file nella tua directory di lavoro che non è presente nel tuo ultimo snapshot o nella tua area di staging. Quando cloni per la prima volta un repository, tutti i tuoi file sono tracciati e non modificati perché li hai appena prelevati e non hai modificato ancora niente.
Quando modifichi i file, Git li vede come cambiati, perché li hai modificati rispetto all’ultimo commit. Parcheggi questi file e poi esegui il commit di tutti i cambiamenti presenti nell’area di stage, ed il ciclo si ripete. Questo ciclo di vita è illustrato nella Figura 2-1.
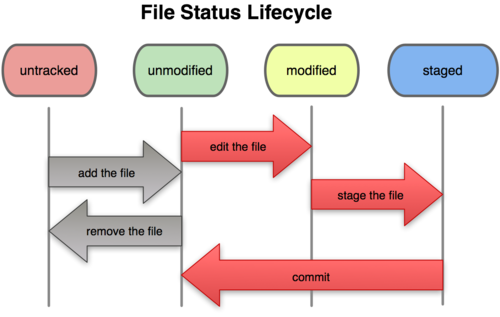
Figure 2-1. Il ciclo di vita dello stato dei tuoi file.
Controlla lo stato dei tuoi file
Lo strumento principale che userai per determinare quali file sono in un certo stato è il comando git status. Se lanci questo comando direttamente dopo aver fatto una clonazione, dovresti vedere qualcosa di simile a:
$ git status
# On branch master
nothing to commit (working directory clean)Questo significa che hai una directory di lavoro pulita — in altre parole, non c’è traccia di file modificati. Git inoltre non vede altri file non tracciati, altrimenti sarebbero elencati qui. Infine, il comando ci dice in quale ramo (branch) si è. Per ora, è sempre il master, che è il predefinito; non preoccuparti ora di questo. Il prossimo capitolo tratterà delle ramificazioni e dei riferimenti nel dettagli.
Ora diciamo che hai aggiunto un nuovo file al tuo progetto, un semplice file README. Se il file non esisteva prima, e lanci git status, vedrai il tuo file non tracciato come segue:
$ vim README
$ git status
# On branch master
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# README
nothing added to commit but untracked files present (use "git add" to track)Puoi vedere che il tuo nuovo file README non è tracciato, perché è sotto al titolo “Untracked files” nell’output degli stati. Untracked fondamentalmente significa che Git vede un file che non avevi nel precedente snapshot (commit); Git non inizierà ad includerlo negli snapshot dei tuoi commit fino a quando tu non glielo dirai esplicitamente. Si comporta così per evitare che tu accidentalmente includa file binari generati o qualsiasi altro tipo di file che non vuoi sia incluso. Se vuoi includere il file README, continua con il tracciamento dei file.
Tracciare nuovi file
Per iniziare a tracciare un nuovo file, usa il comando git add. Per tracciare il file README, lancia questo comando:
$ git add READMESe lanci nuovamente il comando di stato, puoi vedere il tuo file README tracciato e parcheggiato:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
#Ti dice che è parcheggiato (in stage) perché è sotto al titolo “Changes to be committed”. Se fai ora il commit, la versione del file al momento in cui hai lanciato git add sarà quella che troverai nella storia dello snapshot. Ti ricordo che precedentemente è stato lanciato git init, poi hai dovuto lanciare git add (files) — che era l’inizio per tracciare i file nella tua directory. Il comando git add prende il nome del path di ogni file o directory; se è una directory, il comando aggiunge tutti i file in quella directory ricorsivamente.
Parcheggiare file modificati
Ora modifichiamo un file che è già stato tracciato. Se modifichi un file precedentemente tracciato chiamato benchmarks.rb e poi avvii nuovamente il comando status, otterrai qualcosa di simile a:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: benchmarks.rb
#Il file benchmarks.rb appare sotto la sezione chiamata “Changes not staged for commit” — che significa che un file che è tracciato è stato modificato nella directory di lavoro ma non ancora messo in stage (parcheggiato). Per parcheggiarlo, avvia il comando git add (è un comando multifunzione — è usato per iniziare a tracciare nuovi file, per parcheggiare i file e per fare altre cose come eseguire la fusione dei file che entrano in conflitto dopo che sono stati risolti). Avvia dunque git add per parcheggiare ora il file benchmarks.rb, e avvia nuovamente git status:
$ git add benchmarks.rb
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
# modified: benchmarks.rb
#Entrambi i file sono parcheggiati ed entreranno nel prossimo commit. A questo punto, supponendo che tu ti sia ricordato di una piccola modifica da fare a benchmarks.rb prima di fare il commit. Apri nuovamente il file ed esegui la modifica, e ora sei pronto per il commit. Come sempre, lanci git status ancora una volta:
$ vim benchmarks.rb
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
# modified: benchmarks.rb
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: benchmarks.rb
#Che succede? Ora benchmarks.rb è elencato sia in stage che non. Come è possibile? E’ saltato fuori che Git ha parcheggiato il file esattamente come se tu avessi avviato il comando git add. Se esegui ora il commit, la versione di benchmarks.rb che verrà inviata nel commit sarà come quella di quando tu hai lanciato il comando git add, non la versione del file che appare nella tua directory di lavoro quando lanci git commit. Se modifichi un file dopo che hai lanciato git add, devi nuovamente avviare git add per parcheggiare l’ultima versione del file:
$ git add benchmarks.rb
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
# modified: benchmarks.rb
#Ignorare file
Spesso, si ha una classe di file che non si vuole automaticamente aggiungere o far vedere come file non tracciati a Git. Ci sono generalmente alcuni file generati automaticamente come i file di log o i file prodotti dalla creazione di un sistema. In questi casi, puoi creare un file chiamato .gitignore con una lista di pattern corrispondente ad essi. Questo è un esempio di file .gitignore:
$ cat .gitignore
*.[oa]
*~La prima linea dice a Git di ignorare qualsiasi file che finisce con .o o .a — file di oggetti o archivi che possono essere il prodotto di una compilazione del tuo codice. La seconda linea dice a Git di ignorare tutti i file che finiscono con la tilde (~), che è usata da alcuni editor di testo come Emacs per marcare i file temporanei. Puoi anche includere directory di log, tmp o pid; documentazioni generate automaticamente; e così via. Imposta un file .gitignore prima di di procedere è generalmente una buona idea, così si evita il rischio di eseguire accidentalmente dei commit dei file che non vuoi nel tuo repository Git.
Le regole per i pattern che puoi mettere nel file .gitignore sono le seguenti:
- Linee nere o linee che iniziano con # sono ignorate.
- Standard glob pattern funziona.
- Puoi terminare i pattern con un diviso (
/) per specificare una directory. - Puoi negare un pattern aggiungendo all’inizio il punto di esclamazione (
!).
I glob pattern sono semplicemente espressioni regolari usate dalla shell. Un asterisco (*) corrisponde a zero o più caratteri; [abc] corrispondente ad ogni carattere all’interno delle parentesi (in questo caso a, b, o c); il punto di domanda (?) corrispondente ad un singolo carattere; ed i caratteri all’interno delle parentesi quadre separati dal segno meno ([0-9]) corrispondono ad ogni carattere all’interno del range impostato (in questo caso da 0 a 9).
Questo è un altro esempio di file .gitignore:
# un commento - questo è ignorato
*.a # no file .a
!lib.a # ma traccia lib.a, mentre vengono ignorati tutti i file .a come sopra
/TODO # ignora solamente il file TODO in root, non del tipo subdir/TODO
build/ # ignora tutti i file nella directory build/
doc/*.txt # ignora doc/note.txt, ma non doc/server/arch.txtVisualizza le tue modifiche parcheggiate e non
Se il comando git status è troppo vago per te — vorrai conoscere esattamente cosa hai modificato, non solamente i file che hai cambiato — puoi usare il comando git diff. Scopriremo in maggior dettaglio git diff più avanti; ma probabilmente lo userai più spesso per rispondere a queste due domande: Cosa hai modificato ma non ancora parcheggiato? E cosa hai parcheggiato e che sta per mettere nel commit? Certamente, git status risponde a queste domande in generale, git diff ti mostra le linee esatte aggiunte e rimosse — la patch, per così dire.
Nuovamente ti chiedo di modificare e parcheggiare il file README e poi modificare il file benchmarks.rb senza parcheggiarlo. Se lanci il comando status, vedrai nuovamente questo:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: benchmarks.rb
#Per vedere cosa hai modificato ma non ancora parcheggiato, digita git diff senza altri argomenti:
$ git diff
diff --git a/benchmarks.rb b/benchmarks.rb
index 3cb747f..da65585 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -36,6 +36,10 @@ def main
@commit.parents[0].parents[0].parents[0]
end
+ run_code(x, 'commits 1') do
+ git.commits.size
+ end
+
run_code(x, 'commits 2') do
log = git.commits('master', 15)
log.sizeQuesto comando compara cosa c’è nella tua directory di lavoro con quello che è nella tua area di stage. Il risultato ti dice i cambiamenti che hai fatto che non sono ancora stati parcheggiati.
Se vuoi vedere cosa hai parcheggiato e che sarà inviato con il tuo prossimo commit, puoi usare git diff --cached. (Nella versione 1.6.1 e successive di Git, puoi usare anche git diff --staged, che dovrebbe essere più facile da ricordare.) Questo comando compara i tuoi cambiamenti nell’area di stage ed il tuo ultimo commit:
$ git diff --cached
diff --git a/README b/README
new file mode 100644
index 0000000..03902a1
--- /dev/null
+++ b/README2
@@ -0,0 +1,5 @@
+grit
+ by Tom Preston-Werner, Chris Wanstrath
+ http://github.com/mojombo/grit
+
+Grit is a Ruby library for extracting information from a Git repositoryE’ importante notare che git diff di per se non visualizza tutti i cambiamenti fatti dal tuo ultimo commit — solo i cambiamenti che ancora non sono parcheggiati. Questo può confondere, perché se hai messo in stage tutte le tue modifiche, git diff non darà nessun output.
Per un altro esempio, se parcheggi il file benchmarks.rb e lo modifichi, puoi usare git diff per vedere i cambiamenti nel file che sono in stage e i cambiamenti che non sono parcheggiati:
$ git add benchmarks.rb
$ echo '# test line' >> benchmarks.rb
$ git status
# On branch master
#
# Changes to be committed:
#
# modified: benchmarks.rb
#
# Changes not staged for commit:
#
# modified: benchmarks.rb
#Ora puoi usare git diff per vedere cosa non è ancora parcheggiato
$ git diff
diff --git a/benchmarks.rb b/benchmarks.rb
index e445e28..86b2f7c 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -127,3 +127,4 @@ end
main()
##pp Grit::GitRuby.cache_client.stats
+# test linee git diff --cached per vedere cosa hai parcheggiato precedentemente:
$ git diff --cached
diff --git a/benchmarks.rb b/benchmarks.rb
index 3cb747f..e445e28 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -36,6 +36,10 @@ def main
@commit.parents[0].parents[0].parents[0]
end
+ run_code(x, 'commits 1') do
+ git.commits.size
+ end
+
run_code(x, 'commits 2') do
log = git.commits('master', 15)
log.sizeEseguire il commit delle tue modifiche
Ora la tua area di stage è impostata come volevi, puoi eseguire il commit delle tue modifiche. Ricorda che qualsiasi cosa che non è parcheggiata — qualsiasi file che hai creato o modificato e a cui non hai fatto git add — non andrà nel commit. Rimarranno come file modificati sul tuo disco. In questo caso, l’ultima volta che hai lanciato git status, hai visto che tutto era parcheggiato, così sei pronto ad inviare le tue modifiche con un commit. Il modo più semplice per eseguire il commit è di digitare git commit:
$ git commitFacendo questo lanci l’editor che avevi scelto. (Questo è impostato nella tua shell dalla variabile di ambiente $EDITOR — generalmente vim o emacs, ovviamente puoi configurarlo con qualsiasi altro editor usando il comando git config --global core.editor come visto nel Capitolo 1).
L’editor visualizzerà il seguente testo (questo è un esempio della schermata di Vim):
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README
# modified: benchmarks.rb
~
~
~
".git/COMMIT_EDITMSG" 10L, 283CPuoi vedere che il messaggio predefinito del commit contiene l’ultimo output del comando git status, commentato, e la prima riga in alto è vuota. Puoi rimuovere questi commenti ed inserire il tuo messaggio, o puoi lasciarli così per aiutarti a ricordare cosa hai inviato. (Per avere una nota di ricordo più esplicita puoi passare l’opzione -v a git commit. Facendo questo metterai la differenza del tuo ultimo cambiamento nell’editor così potrai vedere esattamente cosa hai fatto.) Quando esci dall’editor, Git crea il tuo commit con un messaggio (con il commento ed il diff spogliato).
In alternativa, puoi inserire il messaggio del tuo commit in linea con il comando commit specificando dopo di esso l’opzione -m, come segue:
$ git commit -m "Story 182: Fix benchmarks for speed"
[master]: created 463dc4f: "Fix benchmarks for speed"
2 files changed, 3 insertions(+), 0 deletions(-)
create mode 100644 READMEOra hai creato il tuo primo commit! Puoi vedere che il commit ha riportato alcune informazioni sull’operazione: che ramo hai inviato (al master), che checksum SHA-1 ha il commit (463dc4f), quanti file sono stati modificati e le statistiche sulle linee aggiunte e rimosse nel commit.
Ricorda che il commit registra lo snapshot che hai impostato nella tua area di staging. Qualsiasi cosa che non hai parcheggiato rimarrà come modificata; puoi fare un altro commit per aggiungere questi alla storia del progetto. Ogni volta che farai un commit, stai registrando una istantanea del tuo progetto che puoi ripristinare o comparare successivamente.
Saltare l’area di staging
Anche se può essere estremamente utile per amministrare i commit esattamente come li vuoi, l’area di staging è molto più complessa di quanto tu possa averne bisogno nel lavoro normale. Se vuoi saltare l’area di parcheggio, Git fornisce una semplice scorciatoia. Passando l’opzione -a al comando git commit Git automaticamente parcheggia tutti i file che sono già stati tracciati facendo il commit, permettendoti di saltare la parte git add:
$ git status
# On branch master
#
# Changes not staged for commit:
#
# modified: benchmarks.rb
#
$ git commit -a -m 'added new benchmarks'
[master 83e38c7] added new benchmarks
1 files changed, 5 insertions(+), 0 deletions(-)Nota come non hai bisogno, in questo caso, di lanciare git add sul file benchmarks.rb prima del commit.
Rimuovere file
Per rimuovere un file con Git, hai bisogno di rimuoverlo dai file tracciati (più precisamente, rimuoverlo dall’area di staging) e poi di fare il commit. Il comando git rm fa questo ed inoltre rimuove il file dalla tua directory di lavoro così non lo vedrai come un file non tracciato la prossima volta.
Se semplicemente rimuovi il file dalla directory di lavoro, sarà visto sotto l’area “Changes not staged for commit” (cioè, non parcheggiato) dell’output git status:
$ rm grit.gemspec
$ git status
# On branch master
#
# Changes not staged for commit:
# (use "git add/rm <file>..." to update what will be committed)
#
# deleted: grit.gemspec
#Poi, se lanci git rm, parcheggia il file rimosso:
$ git rm grit.gemspec
rm 'grit.gemspec'
$ git status
# On branch master
#
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# deleted: grit.gemspec
#La prossima volta che fai il commit, il file se ne andrà e non sarà più tracciato. Se modifichi il file e lo aggiungi nuovamente all’indice, devi forzarne la rimozione con l’opzione -f. Questa è una caratteristica di sicurezza per prevenire la rimozione accidentale dei dati che non sono ancora stati registrati in uno snapshot e che non possono essere recuperati da Git.
Un’altra cosa utile che potresti voler fare è mantenere il file nel tuo albero di lavoro ma rimuoverlo dall’area di staging. In altre parole, vuoi mantenere il file sul tuo disco ma non vuoi che Git ne mantenga ancora traccia. Questo è particolarmente utile se ti dimentichi di aggiungere qualcosa al tuo file .gitignore ed accidentalmente lo aggiungi, come un lungo file di log od un gruppo di file .a compilati. Per fare questo, usa l’opzione --cached:
$ git rm --cached readme.txtPuoi passare file, directory o glob pattern di file al comando git rm. Questo significa che puoi fare cose come
$ git rm log/\*.logNota la barra inversa (\) di fronte a *. Questo è necessario perché Git ha una sua espansione dei nomi di file in aggiunta all’espansione dei filename della tua shell. Questo comando rimuove tutti i file che hanno l’estensione .log nella directory log/. O puoi fare qualcosa di simile a:
$ git rm \*~Questo comando rimuove tutti i file che finiscono con ~.
Movimenti di file
A differenza di altri sistemi VCS, Git non traccia esplicitamente i movimenti di file. Se rinomini un file in Git, nessun metadata è immagazzinato in Git che ti dirà che hai rinominato il file. Come sempre, Git è abbastanza intelligente da capire il fatto — ci occuperemo di rilevare il movimento dei file dopo.
Perciò crea un pò di confusione il fatto che Git abbia un comando mv. Se vuoi rinominare un file in Git, puoi lanciare qualcosa come
$ git mv file_from file_toe questo lavora bene. Infatti, se lanci qualcosa come questo e guardi lo stato, vedrai che Git considera il file rinominato:
$ git mv README.txt README
$ git status
# On branch master
# Your branch is ahead of 'origin/master' by 1 commit.
#
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# renamed: README.txt -> README
#Ovviamente, questo è equivalente a lanciare qualcosa come:
$ mv README.txt README
$ git rm README.txt
$ git add READMEGit capisce implicitamente che è stato rinominato, così non è un problema rinominare un file in questo modo o con il comando mv. L’unica reale differenza è che mv è un solo comando invece di tre — non è conveniente. Più importante è che tu puoi usare qualsiasi strumento per rinominare un file, ed aggiungere/togliere poi prima di un commit.