Che cos’è un Branch
Per capire veramente il modo con cui Git fa il branching, dobbiamo fare un passo indietro ed esaminare come Git memorizza le sue informazioni. Come puoi ricordare dal capitolo 1, Git non memorizza i dati come una serie di cambiamenti o delta, ma come una serie di istantanee (snapshot).
Quando esegui un commit in Git, Git memorizza un oggetto commit che contiene un riferimento alla snapshot del contenuto che hai inserito, i metadata dell’autore e del messaggio, e zero o più riferimenti al commit (o ai commit) che erano i diretti genitori di questo commit: nessun genitore per il primo commit, un genitore per un commit normale, genitori multipli per un commit che è il risultato di un merge di due o più branches.
Per immaginare questo, presumi di avere una cartella che contiene tre file, li inserisci nell’area di stage ed esegui il commit. Inserendoli nell’area di stage, ad ogni file va aggiunta la checksum (l’hash SHA-1 che abbiamo menzionato nel Capitolo 1), memorizza la versione del file nella repository di Git (Git si riferisce ad essa come blobs), e aggiunge la checksum all’area di stage:
$ git add README test.rb LICENSE $ git commit -m ‘commit iniziale del mio progetto’
Quando crei il commit eseguendo git commit, Git esegue il checksum per ogni sottocartella (in questo caso, solo la cartella radice (root) del progetto) e salva questi tre oggetti nel repository di Git. Dopo Git crea un oggetto commit che ha i metadata e un puntatore alla radice del progetto in modo che possa ricreare questo snapshot quando necessario.
La tua repository Git ora contiene 5 oggetti: un blob per il contenuto di ognuno dei tuoi tre file, un albero che elenca il contenuto della cartella e specifica quali nomi di file sono memorizzati come blobs, e un commit con il riferimento alla cartella radice e a tutti i metadata del commit. Concettualmente i dati nella tua repository di Git dovrebbero essere organizzato in modo simile alla Figura 3.1:
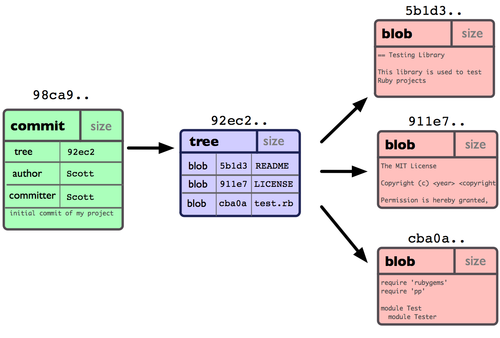
Figura 3-1. Dati di una repository di un singolo commit.
Se fai qualche cambiamento ed esegui nuovamente il commit, il successivo commit memorizza un puntatore al commit che viene immediatamente prima di esso. Dopo due o più commit, la tua storia potrebbe assomigliare a quella della Figura 3-2.
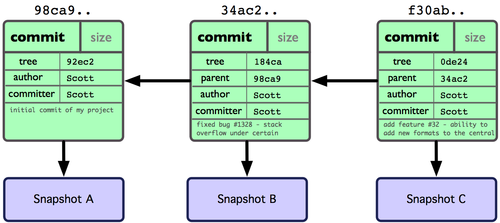
Figura 3-2. Dati di un oggetto Git per commit multipli.
Un branch in Git è semplicemente un leggero puntatore mobile verso uno di questi commit. Il nome del branch di default in Git è master. Iniziando a fare dei commit, ti verrà dato un branch master che punta all’ultimo commit che hai effettuato. Ogni volta che esegui un commit, esso si muove in avanti automaticamente.
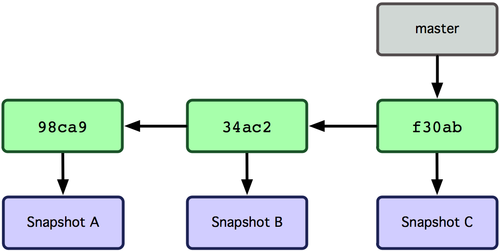
Figura 3-3. Il branch punta alla storia delle informazioni del commit.
Cosa succede se crei uno nuovo branch? Beh, in questo modo crei un nuovo puntatore per te che si muove. Diciamo che crei un nuovo branch di nome testing. Fai questo con il comando git branch
$ git branch testing
Questo crea un nuovo puntatore allo stesso commit sul quale sei (guarda la Figura 3-4).
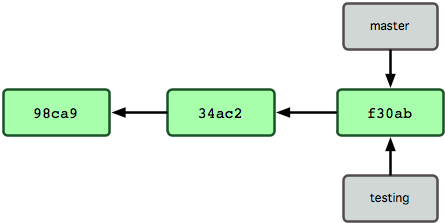
Figura 3-4. Branch multipli puntano alla storia delle informazioni del commit.
Come fa Git a sapere su quale branch sei attualmente? Esso mantiene uno speciale puntatore chiamato HEAD. Nota che questo è molto differente dal concetto di HEAD in altri VCS che potresti aver usato, come Subversion o CVS. In Git, questo è un puntatore al branch locale sul quale sei attualmente. In questo caso, sei ancora sul master. Il comando git branch crea soltanto un nuovo branch - non ti sposta su questo branch (guarda la Figura 3-5).
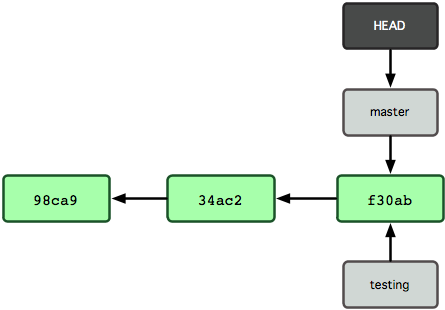
Figura 3-5. L’HEAD del file punta sul branch sul quale sei.
Per spostarti su un branch esistente, esegui il comando git checkout. Spostiamoci sul nuovo branch testing:
$ git checkout testing
Questo sposta l’HEAD, facendolo puntare sul branch testing (guarda la Figura 3-6).
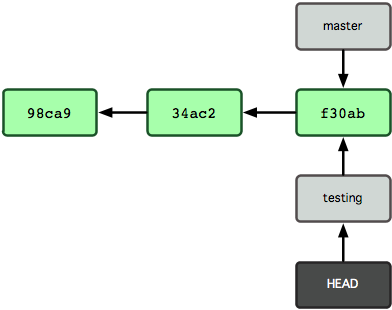
Figura 3-6. L’HEAD punta ad un altro branch quando sposti i branch.
Cosa significa? Beh, facciamo un altro commit:
$ vim test.rb $ git commit -a -m ‘made a change’
La Figura 3-7 illustra il risultato.
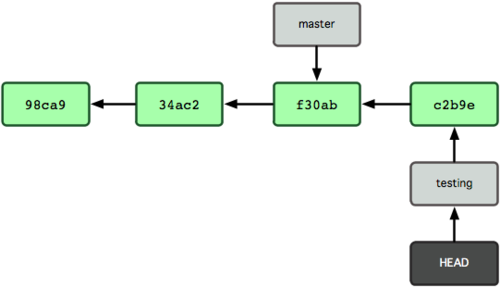
Figura 3-7. Il branch al quale punta l’HEAD si muove in avanti per ogni commit.
Questo è interessante, perchè ora il tuo branch testing si è mosso in avanti, ma il branch master punta ancora al commit sul quale eri quando hai eseguito git checkout per cambiare branch. Spostiamoci nuovamente al branch master:
$ git checkout master
La Figura 3-8 mostra il risultato:
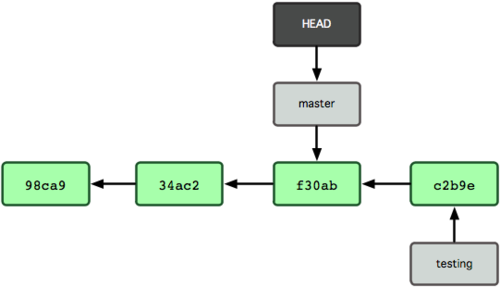
Figura 3-8. L’HEAD si muove in un altro branch con il checkout.
Questo comando ha fatto due cose. Ha spostato il puntatore dell’HEAD nuovamente sul branch master, e ha ripristinato i file nella tua cartella di lavoro allo snapshot al quale il master punta. Questo significa anche che i cambiamenti che fai da questo punto in poi si discosteranno da una più vecchia versione del progetto. Essenzialmente questo riavvolge il lavoro che hai fatto provvisoriamente nel tuo branch testing in modo che tu possa andare in una direzione differente.
Facciamo alcune modifiche ed eseguiamo nuovamente il commit:
$ vim test.rb $ git commit -a -m ‘apportate altre modifiche’
Ora la storia del tuo progetto si è discostata (guarda la Figura 3.9). Hai creato e ti sei spostato su un branch, hai fatto un po’ di lavoro su di esso, e dopo esserti spostato nuovamente al tuo branch principale hai fatto altro lavoro. Questi due cambiamenti sono isolati in branch separati: puoi spostarti indietro o avanti tra i branch e fonderli insieme quando sei pronto. E hai fatto tutto questo con i semplici comandi branch e checkout.
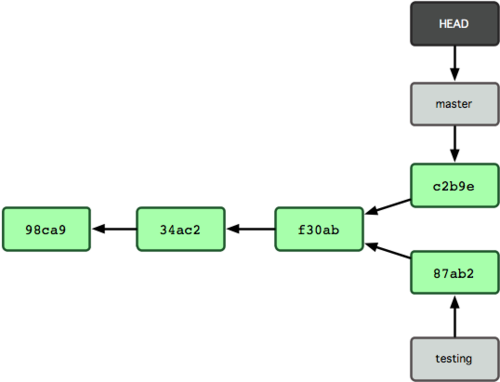
Figura 3-9. La storia dei branch sono divergenti.
Dato che un branch in Git è in realtà un semplice file che contiene i 40 caratteri del checksum della codifica SHA-1 del commit a cui punta, i branch sono economici da creare e distruggere. Creare un nuovo branch è veloce è semplice come scrivere 41 byte in un file (40 caratteri e una nuova linea (newline)).
Questo è in netto contrasto con la maggior parte degli strumenti branch dei VCS, che coinvolge la copia di tutti i file del progetto in una seconda cartella. Questo può impiegare parecchi secondi o addirittura minuti, in base alla grandezza del progetto, mentre in Git il processo è sempre istantaneo. Inoltre, poichè stiamo registrando i genitori quando eseguiamo il commit, trovare una base adeguata per il merge è automaticamente fatto per noi ed è veramente facile farlo. Queste caratteristiche aiutano ad incoraggiare gli sviluppatori a creare ed utilizzare i branch spesso.
Vediamo perchè dovreste farlo.