Contribuire ad un Progetto
Sai quali sono i diversi worlflows, e dovresti avere chiari i fondamentali utilizzi di Git. In questa sezione, parleremo di alcuni metodi comuni per contribuire ad un progetto.
La difficoltà maggiore nel descrivere questo processo, è che ci sono molte variazioni su come può venir fatto. Data la natura flessibile di Git, la gente può lavorare insieme in molti modi, ed è difficile descrivere come dovresti contribuire ad un progetto - ogni progetto è diverso. Alcune delle variabili coinvolte sono la quantità di contributori attivi, il workflow deciso, il tuo tipo di accesso per commit, ed eventualmente il metodo di contribuzione esterno.
La prima variabile è il numero di contributori attivi. Quando utenti attivamente contribuiscono con del codice a questo progetto, e quanto spesso? In molte situazioni avrai una manciata di sviluppatori con alcuni commits al giorno, o forse meno per dei progetti meno attivi. Per azienda o progetti davvero grandi, il numero di sviluppatori potrebbe essere nell’ordine delle migliaia, con dozzine o addirittura di centinaia di patches in arrivo ogni giorno. Questo è importante perché con più sviluppatori vai incontro a più problemi nell’applicare le modifiche in maniera pulita. I cambiamenti che fai potrebbero essere stati resi obsoleti o corrotti da altri che sono stati uniti mentre aspettavi che il tuo lavoro venisse approvato a applicato. Come si può tenere il proprio codice aggiornato e le proprie modifiche valide?
La prossima variabile è il workflow in uso nel progetto. E’ centralizzato, con ogni sviluppatore avente lo stesso tipo di accesso in scrittura nel repository principale? Il progetto ha un manager d’integrazione che controlla tutte le modifiche? Tutte le modifiche sono riviste da più persone ed approvate? Sei coinvolto in questo processo? E’ un sistema con dei tenenti, e devi fornire a loro il tuo lavoro innanzitutto?
Il problema successivo è il tuo accesso per il commit. Il workflow richiesto per poter contribuire al progetto è molto diverso a seconda del fatto che tua abbia accesso in scrittura o no. Se non hai accesso in scrittura, come viene preferito il lavoro dei contributori? Esiste qualche regola a riguardo? Quando contribuisci per volta? Quanto spesso?
Tutte queste domande possono influire effettivamente sul progetto e sul tipo di workflow preferibile per la tua situazione. Coprirò aspetti di ognuno di questi in una serie di casi d’uso, spaziando dal semplice al complesso; dovresti essere capace di ricostruire il workflow specifico per il tuo caso basandoti sugli esempi.
Linee guida per il commit
Prima di guardare ai casi specifici, una breve nota riguardo ai messaggi di commit. Avere una linea guida per creare commit e aderirvi rende il lavoro con Git e la collaborazione con altri molto più semplice. Il progetto Git fornisce un documento che da alcuni suggerimenti per la creazione di messaggi di commit - puoi leggerlo nel codice sorgente di Git nel file Documentation/SubmittingPatches.
Innanzitutto, non è il caso di inserire spazi bianchi. Git fornisce un modo semplice per cercarli - prima di un commit, esegui git diff --check, che identifica possibili errori riguardanti spazi bianchi e li lista per te. Qui c’è un esempio, dove ho sistituiro il colore rosso del terminale con delle lettere X:
$ git diff --check
lib/simplegit.rb:5: trailing whitespace.
+ @git_dir = File.expand_path(git_dir)XX
lib/simplegit.rb:7: trailing whitespace.
+ XXXXXXXXXXX
lib/simplegit.rb:26: trailing whitespace.
+ def command(git_cmd)XXXXSe esegui quel commando prima del commit, puoi vedere se stai per inserire degli spazi bianchi che potrebbero infastidire altri sviluppatori.
In seguito, prova a rendere ogni commit un insieme logico di cambiamenti. Se puoi, cerca di rendere i cambiamenti “digeribili” - non scrivere codice per un intero weekend su cinque diversi problemi e poi fare un commit massivo il Lunedì. Anche se non esegui commit nel weekend, usa l’area di staging il Lunedì per suddividere il tuo lavoro in almeno un commit per problema, con un utile messaggio. Se diverse modifiche coinvolgono lo stesso file, usa git add --patch per aggiungere file in maniera parziale all’area di staging (spiegato nel dettaglio nel capitolo 6). Il risultato finale sarà lo stesso sia che tu faccia un commit sia che tu ne faccia cinque, finché tutti i cambiamenti sono aggiunti ad un certo punto, per cui cerca di rendere le cose più semplici ai tuoi colleghi sviluppatori quando devono controllare i tuoi cambiamenti. Questo approccio inoltre rende più semplice includere o escludere uno dei cambiamenti nel caso ti serva in seguito. Il capitolo 6 descrive una manciata di utili trucchetti di Git per riscrivere la storia ed aggiungere files all’area di staging in maniera interattiva - usa questi strumenti per mantenere una comprensibile cronologia.
L’ultima cosa da tenere in mente è il messaggio di commit. Prendere l’abitudine di creare messaggi di commit di qualità rende usare e collaborare tramite Git molto più semplice. Come regola generale, i tuoi messaggi dovrebbero iniziare con una singola linea di al massimo 50 caratteri che descrive il set di cambiamenti in maniera concisa, seguito da una linea bianca, ed in seguito una spiegazione dettagliata. Il progetto Git richiede che la spiegazione dettagliata includa il motivo del cambiamento ed il confronto con il comportamento precedente - questa è una buona linea guida da seguire. E’ anche una buona idea usare la forma imperativa nel messaggio. In altre parole, usa dei comandi. Al posto di “Ho aggiunto dei test per” oppure “Aggiungere dei test per”, usa “Aggiunti dei test per”. Questo è un modello scritto originariamente da Tim Pope su tpope.net:
Breve (50 caratteri o meno) riassunto delle modifiche
Testo di spiegazione più dettagliato, se necessario. Suddividilo ogni circa 72 caratteri. In alcuni contesti, la prima linea è trattata come l’oggetto di un’email, ed il resto come il contenuto. La linea vuota che separa il riassunto dal testo è importante (a meno che tu non ometta il testo del tutto); strumenti come rebase possono andare in confusione senza di essa.
Ulteriore paragrafo dopo alcune linee vuote.
- Le liste puntate sono concesse
- Di solito un trattino od un asterisco viene usato come separatore, preceduto da uno spazio singolo, con linee vuote tra i punti, ma le convenzioni potrebbero variare in questo caso
Se tutti i tuoi messaggi di commit hanno questo aspetto, le cose saranno molto più semplici per per te e gli sviluppatore con cui lavori. Il progetto Git ha dei messaggi di commit ben formattati - ti incoraggio ad eseguire git log --no-merges per vedere qual’è l’aspetto di una cronologia ben leggibile.
Nei seguenti esempi, ed attraverso la maggior parte di questo libro, per brevità non formatterò i messaggi così accuratamente; invece userò l’opzione -m di git commit. Fa come dico, non come faccio.
Piccoli team privati
La configurazione più semplice e facile da incontrare è il progetto privato con uno o due sviluppatori. Con privato, intendo codice a sorgente chiuso - non accessibile dal resto del mondo. Tu e gli altri sviluppatori avete tutti accesso per il push verso il repository.
In questo ambiente, puoi utilizzare un workflow simile a quello che magari stai già usando con Subversion od un altro sistema centralizzato. Hai ancora i vantaggi (ad esempio) di poter eseguire commit da offline e la creazione di rami (ed unione degli stessi) molto più semplici, ma il workflow può restare simile; la differenza principale è che, nel momento del commit, l’unione avviene nel tuo repository piuttosto che in quello sul server. Vediamo come potrebbe essere la situazione quando due sviluppatori iniziano a lavorare insieme con un repository condiviso. Il primo sviluppatore, John, clona in repository, fa dei cambiamenti ed esegue il commit localmente. (Sostituisco il messaggio di protocollo con ... in questi esempi per brevità.)
# Computer di John
$ git clone john@githost:simplegit.git
Initialized empty Git repository in /home/john/simplegit/.git/
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'rimosso valore di default non valido'
[master 738ee87] rimosso valore di default non valido
1 files changed, 1 insertions(+), 1 deletions(-)Il secondo sviluppatore, Jessica, fa la stessa cosa - clona il repository ed esegue dei cambiamenti:
# Computer di Jessica
$ git clone jessica@githost:simplegit.git
Initialized empty Git repository in /home/jessica/simplegit/.git/
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'aggiunto il processo di reset'
[master fbff5bc] aggiunto il processo di reset
1 files changed, 1 insertions(+), 0 deletions(-)Ora, Jessica esegue un push del suo lavoro nel server:
# Computer di Jessica
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> masterAnche John cerca di eseguire un push:
# Computer di John
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'A John non è consentito eseguire un push perché Jessica ha fatto lo stesso nel frattempo. Questo è particolarmente importante se sei abituato a Subversion, perché avrai notato che i due sviluppatori non hanno modificato lo stesso file. Anche se Subversion automaticamente esegue questa unione nel server se differenti file sono stati modificati, in Git devi unire i cambiamenti localmente. John deve recuperare i cambiamenti di Jessica ed unirli ai suoi prima di poter eseguire il push:
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/masterA questo punto, il repository locale di John somiglia a quello di figura 5-4.
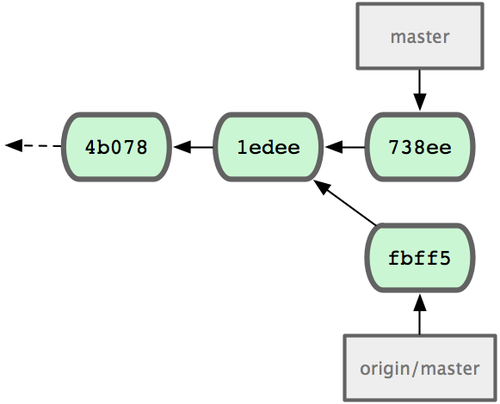
Figura 5-4. Il repository iniziale di John.
John ha a disposizione i cambiamenti che Jessica ha eseguito, ma deve unirli ai suoi prima di avere la possibilità di eseguire un push:
$ git merge origin/master
Merge made by recursive.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)L’unione fila liscia - ora la cronologia dei commit di John sarà come quella di Figura 5-5.
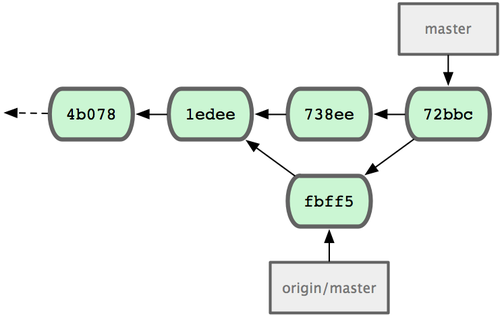
Figura 5-5. Il repository di John dopo aver unito origin/master.
Ora, John può testare il suo codice per essere sicuro che funzioni anche correttamente e può eseguire il push del tutto verso il server:
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> masterInfine, la cronologia dei commit di John somiglierà a quella di figura 5-6.
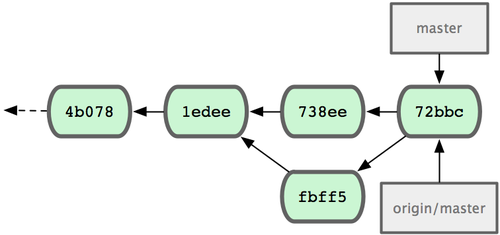
Figura 5-6. La cronologia di John dopo avere eseguito il push verso il server.
Nel frattempo, Jessica sta lavorando su un altro ramo. Ha creato un ramo chiamato problema54 ed ha eseguito tre commit su quel ramo. Non ha ancora recuperato i cambiamenti di John, per cui la sua cronologia di commit è quella di Figura 5-7.
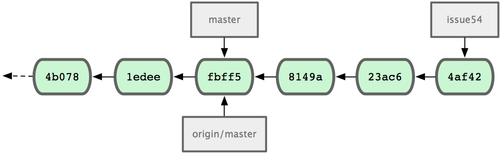
Figura 5-7. La cronologia iniziale di Jessica.
Jessica vuole sincronizzarsi con John, così recupera:
# Computer di Jessica
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/masterQuesto recupera il lavoro che John ha eseguito nel frattempo. La cronologia di Jessica ora è quella di Figura 5-8.
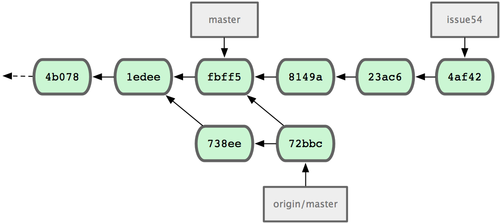
Figura 5-8. La cronologia di Jessica dopo aver recuperato i cambiamenti di John.
Jessica pensa che il suo ramo sia pronto, però vuole sapere con cosa deve unire il suo lavoro prima di eseguire il push. Esegue git log per scoprirlo:
$ git log --no-merges origin/master ^problema54
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
rimosso valore di default non validoOra, Jessica può unire il suo lavoro al ramo master, unire il lavoro di John (origin/master) nel suo ramo master, e poi eseguire il push verso il server di nuovo. Per prima cosa, torna nel suo ramo master per integrare il suo lavoro:
$ git checkout master
Switched to branch "master"
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.Può unire sia origin/master che problema54 per primo - sono entrambi a monte, per cui l’ordine non conta. Il risultato finale sarà lo stesso a prescindere dall’ordine scelto; solo la cronologia sarà leggermente differente. Lei sceglie di unire problema54 per primo:
$ git merge problema54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)Non ci sono problemi; come puoi vederem è stato tutto semplice. Ora Jessica unisce il lavoro di John (origin/master):
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)Tutto viene unito correttamente, e la cronologia di Jessica è come quella di Figura 5-9.
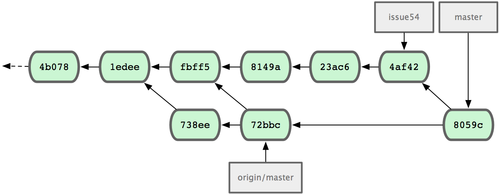
Figura 5-9. La cronologia di Jessica dopo aver unito i cambiamenti di John.
Ora origin/master è raggiungibile dal ramo master di Jessica, cosicché lei sia capace di eseguire dei push successivamente (assumento che John non abbia fatto lo stesso nel frattempo):
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> masterOgni sviluppatore ha eseguito alcuni commit ed unito il proprio lavoro con quello di altri con successo; vedi Figura 5-10.
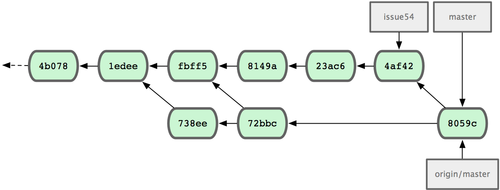
Figura 5-10. La cronologia di Jessica dopo aver eseguito il push dei cambiamenti verso il server.
Questo è uno dei workflow più semplici. Lavori per un pò, generalmente in un ramo, ed unisci il tutto al ramo master questo è pronto ad essere integrato. Quando vuoi condividere il tuo lavoro, uniscilo al tuo ramo master, poi recupera ed unisci origin/master se è cambiato, ed infine esegui il push verso il ramo master nel server. La sequenza è simile a quella di Figura 5-11.
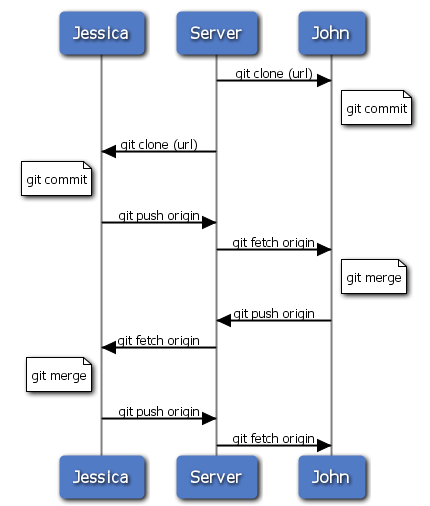
Figura 5-11. La sequenza generale di eventi per un semplice workflow con Git a più sviluppatori.
Team privato con manager
In questo prossimo scenario, scoprirai ai ruoli di un contributore in un gruppo privato più grande. Imparerai come lavorare in un ambiente dove piccoli gruppi collaborano a delle funzionalità e poi queste contribuzioni sono integrate da un altro componente.
Supponiamo che John e Jessica stiano lavorando insieme su una funzionalità, mentre Jessica e Josie si stanno concentrando su una seconda. In questo caso, l’azienda sta usando un workflow con manager d’integrazione dove il lavoro di ogni gruppo è integrato solo da certi ingegneri, ed il ramo master del repository principale può essere aggiornato solo dai suddetti ingegneri. In questo scenario, tutto il lavoro è eseguito sui rami suddivisi per team, ed unito dagli integratori in seguito.
Seguiamo il workflow di Jessica mentre lavora sulle due funzionalità, collaborando parallelamente con due diversi sviluppatori in questo ambiente. Assumendo che lei abbia già clonato il suo repository, decide di lavorare su funzionalitaA per prima. Crea un nuovo ramo per la funzionalità ed esegue del lavoro su di esso.
# Computer di Jessica
$ git checkout -b featureA
Switched to a new branch "funzionalitaA"
$ vim lib/simplegit.rb
$ git commit -am 'aggiunto il limite alla funzione di log'
[featureA 3300904] aggiunto il limite alla funzione di log
1 files changed, 1 insertions(+), 1 deletions(-)A questo punto, lei ha bisogno di condividere il suo lavoro con John, così lei esegue il push del ramo funzionalitaA sul server. Jessica non ha accesso per il push al ramo master - solo gli integratori ce l’hanno - perciò deve eseguire il push verso un altro ramo per poter collaborare con John:
$ git push origin funzionalitaA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureAJessica manda una e-mail a John dicendogli che ha eseguito il push del suo lavoro in un ramo chiamato funzioanlitaA e lui può dargli un’occhiata. Mentre aspetta una risposta da John, Jessica decide di iniziare a lavorare su funzionalitaB con Josie. Per iniziare, crea un nuovo ramo basandosi sul ramo master del server:
# Computer di Jessica $ git fetch origin $ git checkout -b featureB origin/master Switched to a new branch “featureB”
Ora, Jessica esegue un paio di commit sul ramo funzionalitaB:
$ vim lib/simplegit.rb
$ git commit -am 'resa la funzione ls-tree ricorsiva'
[featureB e5b0fdc] resa la funziona ls-tree ricorsiva
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'aggiunto ls-files'
[featureB 8512791] aggiunto ls-files
1 files changed, 5 insertions(+), 0 deletions(-)Il repository di Jessica è come quello di Figura 5-12.
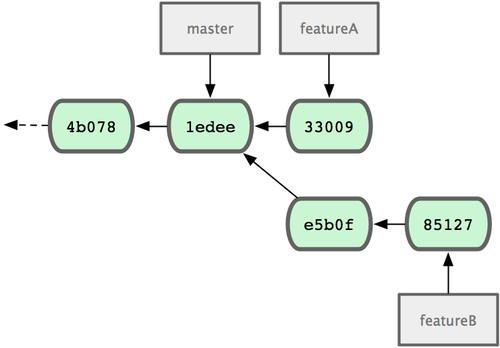
Figura 5.12. La cronologia iniziale dei commit di Jessica Figure 5-12. Jessica’s initial commit history.
Lei è pronta ad eseguire un push del proprio lavoro, ma riceve una e-mail da Josie la quale dice che una parte del lavoro era già stato messo nel server nel ramo chiamato funzionalitaBee. Jessica innanzitutto deve unire questi cambiamenti ai suoi prima di poter eseguire il push verso il server. Può recuperare il lavoro di Josie usando git fetch:
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBeeJessica ora può unire il suo lavoro a quello di Josie con git merge:
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)C’è un problema - deve eseguire il push del suo ramo funzionalitaB verso il ramo funzionalitaBee nel server. Può farlo specificando il ramo locale seguito dal simbolo dei due punti (:) seguito a sua volta dal nome del ramo remoto destinazione del comando git push:
$ git push origin funzionalitaB:funzionalitaBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBeeQuesto è chiamato refSpec. Vedi il capitolo 9 per una discussione più dettagliata sui refspec di Git ed altre cose che puoi fare con loro.
Ora John manda una mail a Jessica dicendo che ha eseguito il push di alcuni cambiamenti sul ramo funzionalitaA e le chiede di controllarli. Lei esegue git fetch per recuperare questi cambiamenti:
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureAOra, lei può vedere cos’è stato cambiato con git log:
$ git log origin/funzionalitaA ^funzionalitaA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
cambianto l'output del log da 30 a 25Finalmente, unisce il lavoro di John al suo sul ramo funzionalitaA:
$ git checkout funzionalitaA
Switched to branch "funzionalitaA"
$ git merge origin/funzionalitaA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)Jessica vuole aggiustare qualcosa, così esegue un altro commit ed un push verso il server:
$ git commit -am 'leggero aggiustamento'
[featureA ed774b3] leggero aggiustamento
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push origin featureA
...
To jessica@githost:simplegit.git
3300904..ed774b3 featureA -> featureAOra la cronologia dei commit di Jessica sarà come quella di Figura 5-13.
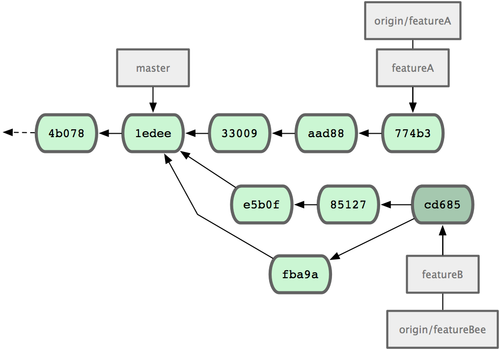
Figura 5-13. La cronologia di Jessica dopo aver eseguito il commit sul ramo.
Jessica, Josie e John informano gli integratori che i rami funzionalitaA e funzionalitaB sono sul server e pronti per l’integrazione nel ramo master. Dopo l’integrazione di questi rami nel master, un recupero del ramo principale aggiungerà anche i nuovi commit, rendendo la cronologia dei commit come quella di figura 5.14.
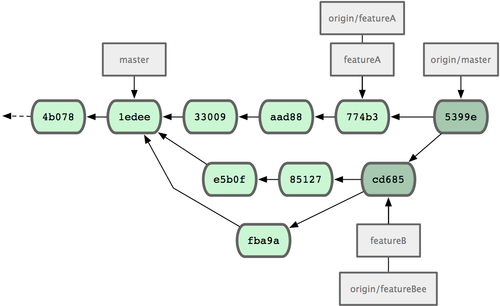
Figura 5.14. La cronologia di Jessica dopo aver unito entrambi i rami.
Molti gruppi migrano verso Git per la sua capacità di avere più team a lavorarare in parallelo, unendo le differenti linee di lavoro alla fine del processo. L’abilità di piccoli sotto gruppi di una squadra di collaborare tramite rami remoti senza necessariamente dover coinvolgere o ostacolare l’intero team è un grande beneficio di Git. La sequenza per il workflow che hai appena visto è rappresentata dalla Figura 5-15.
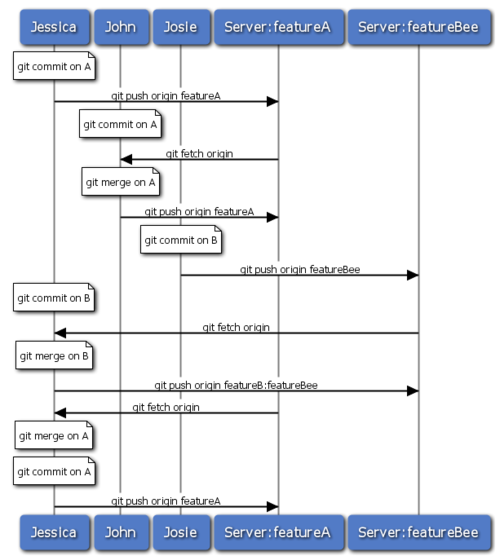
Figura 5-15. Sequenza base di questo workflow con team separati.
Piccolo progetto pubblico
Contribuire ad un progetto pubblico è leggermente differente. Dato che non hai il permesso di aggiornare direttamente i rami del progetto, devi far avere il tuo lavoro ai mantenitori in qualche altro modo. Questo esempio descrive la contribuzione via fork su host Git che lo supportano in maniera semplice. I siti repo.or.cz e GitHub lo supportano, e molti altri mantenitori di progetti si aspettano questo tipo di contribuzione. La prossima sezione si occupa di progetti che preferiscono accettare patch via e-mail
Innanzitutto, probabilemnte dovrai clonare il repository principale, creare un ramo per le modifiche che hai in programma di fare, e fare li il tuo lavoro. La sequenza è grosso modo questa:
$ git clone (url)
$ cd project
$ git checkout -b funzionalitaA
$ (lavoro)
$ git commit
$ (lavoro)
$ git commitPotresti voler usare rebase -i per ridurre il tuo lavoro ad un singolo commit, o riorganizzare il lavoro nei commit per rendere le modifiche semplice da controllare per il mantenitore - vedi il Capitolo 6 per altre informazioni sul rebasing interattivo.
Quando il tuo lavoro sul ramo è completato e sei pronto per farlo avere ai mantenitori, vai alla pagina principale del progetto e clicca sul link “Fork”, creando una tua copia scrivibile del progetto. Dovrai poi aggiungere questo nuovo URL di repository come secondo URL remoto, in questo caso chiamato miofork:
$ git remote add miofork (url)Dovrai eseguire un push del tuo lavoro verso esso. E’ più semplice eseguire il push del ramo su cui stai lavorando piuttosto che unirlo al ramo master ed eseguire il push di quest’ultimo. La ragione è che se il tuo lavoro non è accettato, oppure lo è solo in parte, non dovrai tornare indietro nei commit sul tuo ramo master. Se i mantenitori uniscono, eseguono un rebase, o prendono pezzi dal tuo lavoro, riuscirai in ogni caso a recuperarlo eseguendo un pull dal loro repository:
$ git push myfork funzionalitaAQuando hai eseguito il push del tuo lavoro verso il tuo fork, devi farlo sapere al mantenitore. Questo passaggio è chiamato spesso richiesta di pull (pull request), e puoi farlo sia tramite il sito - GitHub ha un pulsante “pull request” che automaticamente notifica al mantenitore - o eseguire il comando git request-pull ed inviare l’output il mantenitore manualmente.
Il comando request-pull riceve come parametri il ramo base sul quale vuoi far applicare le modifiche ed l’URL del repository Git da cui vuoi estrarle, ed in output fornisce un riassunto di tutte queste modifiche. Per esempio, se Jessica volesse inviare a John una richiesta di pull, e lei ha eseguito due commit sul ramo di cui ha appena effettuato il push, può eseguire questo:
$ git request-pull origin/master miofork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
John Smith (1):
aggiunta una nuova funzione
are available in the git repository at:
git://githost/simplegit.git funzionalitaA
Jessica Smith (2):
aggiunto limite alla funzione di log
cambiato l'output del log da 30 a 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)L’output può essere inviato al mantenitore. Esso riporta da dove è stato creato il nuovo ramo, un riassunto dei commit e dice da dove si può eseguire il pull.
Su un progetto dove non sei il mantenitore, è generalmente comune avere un ramo come master sempre collegato a origin/master ed eseguire il tuo lavoro su rami che puoi eliminare nel caso non venissero accettati. Avere il lavoro suddiviso in rami inoltre rende semplice per te eseguire il rebase del tuo lavoro se è stato modificato il repository principale ed i tuoi commit non possono venire applicati in maniera pulita. Per esempio, se vuoi aggiungere un secondo argomento di lavoro ad un progetto, non continuare a lavorare sul ramo di cui hai appena fatto il push - creane un altro partendo dal ramo master del repository:
$ git checkout -b funzionalitaB origin/master
$ (lavoro)
$ git commit
$ git push miofork funzionalitaB
$ (email al mantenitore)
$ git fetch originOra, ognuno dei tuoi lavori è separato, simile ad una coda di modifiche. Puoi riscrivere, modificare o effettuare un rebase, senza che i rami interferiscano o dipendano l’uno dall’altro, come in Figura 5-16.
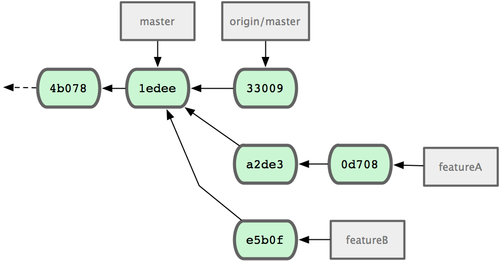
Figura 5-16. Conologia iniziale dei commit con del lavoro su funzionalitaB.
Diciamo che il mantenitore del progetto ha eseguito il pull, una manciata di altre modifiche e provato il tuo primo ramo ma non riesce più ad applicare tali modifiche in maniera pulita. In questo caso, puoi provare ad effettuare un rebase di quel ramo basandoti sul nuovo origin/master, risolvere i conflitti e poi inviare di nuovo i tuoi cambiamenti:
$ git checkout funzionalitaA
$ git rebase origin/master
$ git push –f miofork featureAQuesto riscrive la tua cronologia per farla diventare come quella di Figura 5-17.
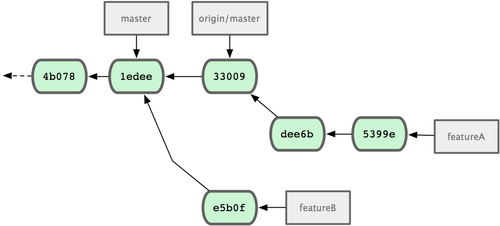
Fgiura 5-17. La cronologia dei commit dopo il lavoro su funzionalitaA.
Dato che hai eseguito un rebase del ramo, devi specificare l’opzione -f per eseguire un push, per poter sostituire il ramo funzionalitaA sul server con un commit che non discende da esso. Un’alternativa potrebbe essere un push di questo nuovo lavoro verso un diverso branch sul server (chiamato ad esempio funzionalitaAv2).
Diamo un’occhiata ad un possibile scenario: il mantenitore ha guardato al tuo lavoro in un secondo ramo, e gradisce il concetto ma vorrebbe che tu cambiassi dei dettagli dell’implementazione. Potresti inoltre cogliere questa opportunità per basarti sul ramo master corrente. Crei un nuovo ramo basato sul corrente origin/master, sposti i cambiamenti di funzionalitaB qui, risolvi i conflitti, cambi l’implementazione, e poi esegui il push come un nuovo ramo:
$ git checkout -b funzionalitaBv2 origin/master
$ git merge --no-commit --squash funzionalitaB
$ (cambia implementazione)
$ git commit
$ git push miofork funzionalitaBv2L’opzione --squash prende tutto il lavoro nel ramo da unire e lo aggiunge come un singolo commit al ramo in cui sei. L’opzione no-commit dice a Git di non eseguire automaticamente il commit. Questo ti consente di aggiungere i cambiamenti da un altro ramo e poi eseguire altre modifiche prima di effettuare il nuovo commit.
Ora puoi inviare al mantenitore un messaggio dicendo che hai effettuato i cambiamenti richiesti e che può trovare nel ramo funzionalitaBv2 (vedi Figura 5-18).
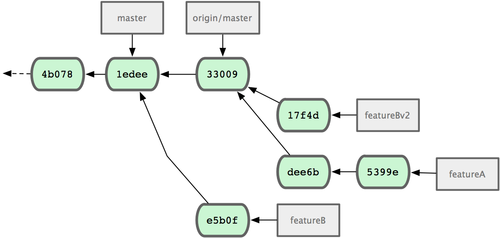
Figura 5-18. La cronologia dei commit dopo il lavoro su funzionalitaBv2.
Grande Progetto Pubblico
Molti grandi progetti hanno definito delle procedure da seguire per poter inviare delle patch. Avrai bisogno di leggere le specifiche regole di ogni progetto, perchè queste potranno differire tra loro. Tuttavia, molti grandi progetti pubblici accettano patch tramite una mailing list degli sviluppatori, quindi tratterò ora un esempio di questo genere.
Il flusso di lavoro è simile ai casi precedenti: crei un ramo per ognuna delle modifiche sulle quali intendi lavorare. La differenza sta in come invii tali modifiche al progetto. Invece di fare un tuo fork del progetto e di inviare le tue modifiche ad esso tramite push, crei una versione e-mail di ognuno dei commit e l invii tramite posta elettronica alla mailing list degli sviluppatori:
$ git checkout -b topicA
$ (work)
$ git commit
$ (work)
$ git commitOra hai due commit che vuoi inviare alla mailing list. Usi git format-patch per generare un file formato mbox che puoi inviare via e-mail alla mailing list. Il comando git format-patch trasforma ogni commit in un messaggio email il cui oggetto è formato dalla prima linea del messaggio del commit e il cui contenuto è il rimanente testo del commit più la patch delle modifiche. La cosa bella di tutto ciò è che applicando i commit da un’email si conservano tutte le informazioni in essi contenute in maniera appropriata, come vedrai meglio nella prossima sezione:
$ git format-patch -M origin/master
0001-add-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patchIl comando format-patch visualizza i nomi dei file patch che vengono creati. Il parametro -M indica a Git di tener traccia dei file rinominati. I file infine hanno questo aspetto:
$ cat 0001-add-limit-to-log-function.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first 20
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
1.6.2.rc1.20.g8c5b.dirtyPuoi anche modificare questi file patch per aggiungere maggiori informazioni per la mailing list che non vuoi vengano visualizzate all’interno del messaggio del commit. Se aggiungi del testo tra le righe contrassegnate da -- e l’inizio della patch (ad esempio la riga lib/simplegit.rb), gli sviluppatori possono leggerlo ma esso verrà escluso dal messaggio del commit con il quale la patch verrà applicata.
Per inviare le patch alla mailing list, puoi copiare ed incollare il file nel tuo programma di posta o inviare il tutto tramite un programma a linea di comando. Incollando il testo spesso si hanno dei problemi di formattazione, sopratutto con client di posta “intelligenti” che non preservano i caratteri di acapo e altri caratteri di spaziatura. Fortunatamente, Git fornisce uno strumento per aiutarti ad inviare le patch in modo corretto tramite IMAP, il che potrebbe risultare più semplice. Ti mostrerò come inviare una patch via Gmail, che è il client di posta che utilizzo io; puoi trovare le istruzioni dettagliate per diversi client di posta alla fine del documento Documention/SubmittingPatches presente nel codice sorgente di Git.
Prima di tutto, devi configurare la sezione imap nel tuo file ~/.gitconfig. Puoi settare ogni valore separatamente con una serie di comandi git config o aggiungerli manualmente al suo interno tramite un editor di testo. Alla fine il tuo file di configurazione dovrebbe essere più o meno così:
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = user@gmail.com
pass = p4ssw0rd
port = 993
sslverify = falseSe il tuo server IMAP non usa SSL, le ultime due righe probabilmente non ti saranno necessarie e il valore del campo host sarà imap:// anzichè imaps://. Quando tutto ciò è configurato, puoi usare git send-email per inviare la serie di patch alla cartella “Bozze” del tuo server IMAP:
$ git send-email *.patch
0001-added-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patch
Who should the emails appear to be from? [Jessica Smith <jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email? yPoi, Git produce alcune informazioni di log che figureranno più o meno così per ogni patch che stai inviando:
(mbox) Adding cc: Jessica Smith <jessica@example.com> from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] added limit to log function
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OKA questo punto, dovresti essere in grado di andare nella tua cartella delle bozze, cambiare il campo “A:” con la mailing list alla quale vuoi inviare la patch, aggiungere in copia il mantenitore del progetto o la persona responsabile per quella determinata sezione ed inviare il codice.
Sommario
Questa sezione ha coperto un certo numero di workflow comuni che è facile incontrare quando si ha a che fare con tipi diversi di progetti Git e ha introdotto un paio di nuovi strumenti che ti possono aiutare a gestire questo processo. Ora, vedrai come si lavora con l’altra faccia della medaglia: mantenere un progetto Git. Imparerai ad essere un dittatore benevolo o integration manager.