De basis van Git
Dus, wat is Git in een notendop? Dit is een belangrijk deelhoofdstuk, omdat het waarschijnlijk een stuk makkelijker wordt om Git effectief te gebruiken als je goed begrijpt wat Git is en hoe het werkt. Probeer te vergeten wat je al weet over andere VCSen zoals Subversion en Perforce als je Git aan het leren bent; zo kan je verwarring door de subtiele verschillen voorkomen. Git gaat op een hele andere manier met informatie om dan die andere systemen, ook al lijken de verschillende commando’s behoorlijk op elkaar. Als je die verschillen begrijpt, kan je voorkomen dat je verward raakt als je Git gebruikt.
Momentopnames in plaats van verschillen
Een groot verschil tussen Git en elke andere VCS (inclusief Subversion en consoorten) is hoe Git denkt over zijn data. Conceptueel bewaren de meeste andere systemen informatie als een lijst van veranderingen per bestand. Deze systemen (CVS, Subversion, Perforce, Bazaar, enzovoort) zien de informatie die ze bewaren als een aantal bestanden en de veranderingen die aan die bestanden zijn aangebracht over de tijd, zoals geïllustreerd in Figuur 1-4.
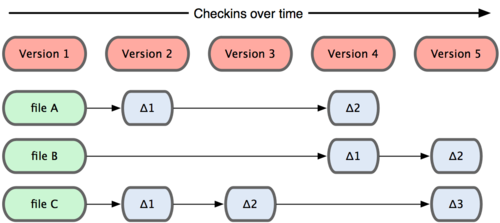
Figuur 1-4. Andere systemen bewaren data meestal als veranderingen aan een basisversie van elk bestand.
Git ziet en bewaart zijn data heel anders. De kijk van Git op zijn data kan worden uitgelegd als een reeks momentopnames van een miniatuurbestandssysteem. Elke keer dat je ‘commit’ - de status van van je project in Git opslaat - neemt het een soort van foto van hoe al je bestanden er op dat moment uitzien en slaat een verwijzing naar die momentopname op. Voor efficiëntie slaat Git ongewijzigde bestanden niet elke keer opnieuw op — alleen een verwijzing naar het eerdere identieke bestand dat het eerder al opgeslagen had. In Figuur 1-5 kan je zie hoe Git ongeveer over zijn data denkt.
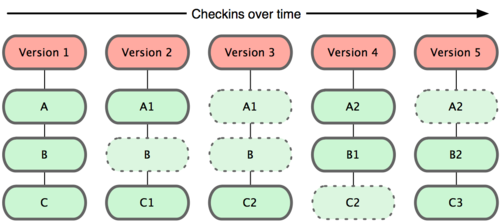
Figuur 1-5. Git bewaart data als momentopnames van het project.
Dat is een belangrijk verschil tussen Git en bijna alle overige VCSen. Hierdoor vindt Git bijna elk onderdeel van versiebeheer opnieuw uit, terwijl de meeste andere systemen het allemaal gewoon overnemen van de eerdere generaties. Hierdoor is Git meer een soort miniatuurbestandssysteem met een paar ongelooflijk krachtige gereedschappen, in plaats van niets meer dan een VCS. We zullen een paar van de voordelen die je krijgt als je op die manier over data denkt gaan onderzoeken, als we ‘branching’ (gesplitste ontwikkeling) toelichten in Hoofdstuk 3.
Bijna alles is lokaal
De meeste handelingen in Git werken alleen op lokale bestanden en bronnen. Normaal gesproken is geen informatie nodig van een andere computer in je netwerk. Als je gewoon bent aan een CVCS, waar de meeste handelingen vertraagd worden door het netwerk, lijkt Git een geschenk van de snelheidsgoden. Omdat je de hele geschiedenis van het project op je lokale harde schijf hebt staan, lijken de meeste acties geen tijd in beslag te nemen.
Een voorbeeld: Git hoeft niet aan een of andere server de geschiedenis van je project te vragen als je de die wilt doorbladeren – het leest simpelweg jouw lokale database. Dat betekent dat je de geschiedenis bijna direct te zien krijgt. Als je de veranderingen wilt zien tussen de huidige versie van een bestand en de versie van een maand geleden kan Git het bestand van een maand geleden opzoeken, en de lokale verschillen berekenen, in plaats van aan een niet-lokale server te moeten vragen om het te doen, of de oudere versie van het bestand ophalen om het lokaal te doen.
Dit betekent dat er maar heel weinig is dat je niet kunt doen als je offline bent of zonder VPN zit. Als je in een vliegtuig of trein zit, en je wilt nog even een beetje werken, kun je vrolijk doorgaan met commits maken tot je een netwerkverbinding krijgt, zodat je je werk kunt uploaden. Als je naar huis gaat en je VPN client niet aan de praat kunt krijgen dan kun je nog steeds doorwerken. Bij veel andere systemen is dat of onmogelijk of zeer onaangenaam. Als je bijvoorbeeld Perforce gebruikt kun je niet zo veel doen als je niet verbonden bent met de server. Met Subversion en CVS kun je bestanden bewerken maar je kunt geen commits maken voor je database (omdat die offline is). Dat lijkt misschien niet zo belangrijk maar je zult nog versteld staan wat een verschil het kan maken.
Git is integer
Git maakt een controlegetal (‘checksum’) van alles voordat het wordt opgeslagen en er wordt later naar die data verwezen met dit controlegetal. Dat betekent dat het onmogelijk is om de inhoud van een bestand of map te veranderen zonder dat Git er vanaf weet. Deze functionaliteit is ingebouwd in het diepste deel van Git en staat centraal in zijn filosofie. Je kunt geen informatie kwijtraken als het wordt verstuurd en bestanden kunnen niet corrupt raken zonder dat Git het weet.
Het mechanisme dat Git gebruikt voor deze controlegetallen heet een SHA-1-hash. Dat is een tekenreeks van 40 karakters lang, bestaande uit hexadecimale tekens (0–9 en a–f) en wordt berekend uit de inhoud van een bestand of mappenstructuur in Git. Een SHA-1-hash ziet er ongeveer zo uit:
24b9da6552252987aa493b52f8696cd6d3b00373Je zult deze hashtekenreeksen overal tegenkomen omdat Git er zoveel gebruik van maakt. Sterker nog, Git bewaart data niet onder hun bestandsnaam maar in de database van Git onder de hash van de inhoud.
Git voegt normaal gesproken alleen data toe
Wanneer je iets doet in Git is de kans groot dat het alleen maar data aan de database van Git toevoegt. Het is erg moeilijk om het systeem iets te laten doen dat je niet ongedaan kan maken of de data uit te laten wissen op wat voor manier dan ook. Zoals met elke VCS kun je veranderingen verliezen of verhaspelen waar je nog geen momentopname van hebt gemaakt; maar als je dat eenmaal hebt gedaan, is het erg moeilijk om die data te verliezen, zeker als je je lokale database regelmatig uploadt (‘push’) naar een andere repository.
Je zult nog veel plezier van Git hebben omdat je weet dat je kunt experimenteren zonder het gevaar te lopen jezelf behoorlijk in de nesten te werken. Zie Hoofdstuk 9 voor een iets diepgaandere uitleg over hoe Git zijn data bewaart en hoe je de data die verloren lijkt kunt terughalen.
De drie toestanden
Let nu goed op. Dit is het belangrijkste dat je over Git moet weten als je wilt dat de rest van het leerproces goed verloopt. Git heeft drie hoofdtoestanden waarin je bestanden zich kunnen bevinden: gecommit (‘commited’), aangepast (‘modified’) en voorbereid voor een commit (‘staged’). Gecommit betekent dat alle data al veilig opgeslagen is in je lokale database. Aangepast betekent dat je je bestand hebt veranderd maar dat je nog geen nieuwe momentopname in je database hebt. Voorbereid betekent dat je al hebt aangegeven dat je de huidige versie van het aangepaste bestand in je volgende momentopname toevoegt.
Dit brengt ons tot de drie hoofdonderdelen van een Gitproject: de Gitmap, de werkmap, en de wachtrij voor een commit (‘staging area’)
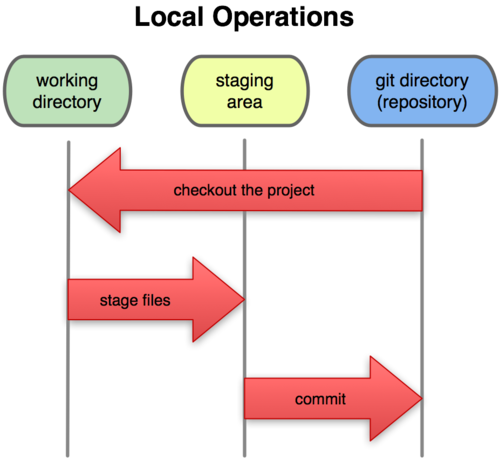
Figuur 1-6. Werkmap, wachtrij en Gitmap
De Gitmap is waar Git de metadata en objectdatabase van je project opslaat. Dit is het belangrijkste deel van Git. Deze map wordt gekopieerd wanneer je een repository kloont vanaf een andere computer.
De werkmap is een kopie van een bepaalde versie van het project (een ‘checkout’). Deze bestanden worden uit de gecomprimeerde database in de Gitmap gehaald en op de harde schijf geplaatst waar jij ze kunt gebruiken of bewerken.
De wachtrij is een simpel bestand, dat zich in het algemeen in je Gitmap bevindt, waar informatie opgeslagen wordt over wat in de volgende commit meegaat. Het wordt soms de index genoemd, maar tegenwoordig wordt het de wachtrij (staging area) genoemd.
De algemene manier van werken met Git gaat ongeveer zo:
- Je bewerkt bestanden in je werkmap.
- Je bereidt de bestanden voor, waardoor momentopnames worden toegevoegd aan de wachtrij.
- Je maakt een commit. Een commit neemt alle momentopnames van de wachtrij en die permanent bewaard in je Gitmap.
Als een bepaalde versie van een bestand in de Gitmap staat, wordt het beschouwd als gecommit. Als het is aangepast, maar wel aan de wachtrij is toegevoegd, is het voorbereid. En als het veranderd is sinds het gekopieerd werd, maar niet voorbereid is, is het aangepast. In Hoofdstuk 2 leer je meer over deze toestanden en hoe je er voordeel van kunt hebben, maar ook hoe je de wachtrij compleet over kunt slaan.