Czym jest gałąź
Żeby naprawdę zrozumieć sposób, w jaki Git obsługuje gałęzie, trzeba cofnąć się o krok i przyjrzeć temu, w jaki sposób Git przechowuje dane. Jak może pamiętasz z Rozdziału 1., Git nie przechowuje danych jako serii zmian i różnic, ale jako zestaw migawek.
Kiedy zatwierdzasz zmiany w Gicie, ten zapisuje obiekt zmian (commit), który z kolei zawiera wskaźnik na migawkę zawartości, która w danej chwili znajduje się w poczekalni, metadane autora i opisu oraz zero lub więcej wskaźników na zmiany, które były bezpośrednimi rodzicami zmiany właśnie zatwierdzanej: brak rodziców w przypadku pierwszej, jeden w przypadku zwykłej, oraz kilka w przypadku zmiany powstałej wskutek scalenia dwóch lub więcej gałęzi.
Aby lepiej to zobrazować, załóżmy, że posiadasz katalog zawierający trzy pliki, które umieszczasz w poczekalni, a następnie zatwierdzasz zmiany. Umieszczenie w poczekalni plików powoduje wyliczenie sumy kontrolnej każdego z nich (skrótu SHA-1 wspomnianego w Rozdziale 1.), zapisanie wersji plików w repozytorium (Git nazywa je blobami) i dodanie sumy kontrolnej do poczekalni:
$ git add README test.rb LICENSE
$ git commit -m 'Początkowa wersja mojego projektu'Kiedy zatwierdzasz zmiany przez uruchomienie polecenia git commit, Git liczy sumę kontrolną każdego podkatalogu (w tym wypadku tylko głównego katalogu projektu) i zapisuje te trzy obiekty w repozytorium. Następnie tworzy obiekt zestawu zmian (commit), zawierający metadane oraz wskaźnik na główne drzewo projektu, co w razie potrzeby umożliwi odtworzenie całej migawki.
Teraz repozytorium Gita zawiera już 5 obiektów: jeden blob dla zawartości każdego z trzech plików, jedno drzewo opisujące zawartość katalogu i określające, które pliki przechowywane są w których blobach, oraz jeden zestaw zmian ze wskaźnikiem na owo drzewo i wszystkimi metadanymi. Jeśli chodzi o ideę, dane w repozytorium Gita wyglądają jak na Rysunku 3-1.
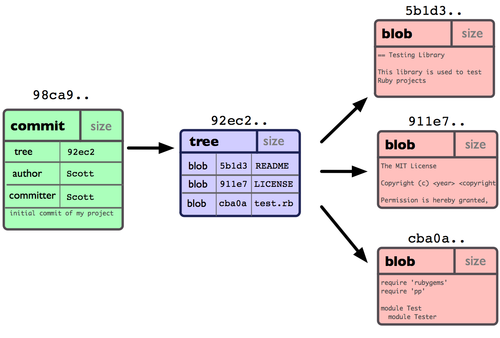
Figure 3-1. Dane repozytorium z jedną zatwierdzoną zmianą.
Jeśli dokonasz zmian i je również zatwierdzisz, kolejne zatwierdzenie zachowa wskaźnik do zestawu zmian, który został utworzony bezpośrednio przed właśnie dodawanym. Po dwóch kolejnych zatwierdzeniach, twoja historia może wyglądać podobnie do przedstawionej na Rysunku 3-2:
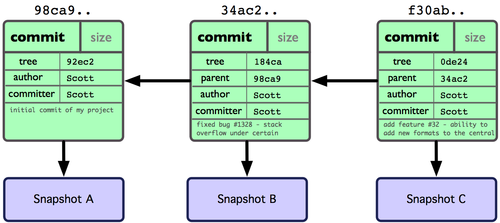
Figure 3-2. Dane Gita dla wielu zestawów zmian.
Gałąź w Gicie jest po prostu lekkim, przesuwalnym wskaźnikiem na któryś z owych zestawów zmian. Domyślna nazwa gałęzi Gita to master. Kiedy zatwierdzasz pierwsze zmiany, otrzymujesz gałąź master, która wskazuje na ostatni zatwierdzony przez ciebie zestaw. Z każdym zatwierdzeniem automatycznie przesuwa się ona do przodu.
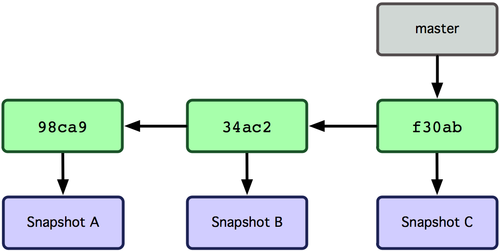
Figure 3-3. Gałąź wskazująca na dane zestawu zmian w historii.
Co się stanie, jeśli utworzysz nową gałąź? Cóż, utworzony zostanie nowy wskaźnik, który następnie będziesz mógł przesuwać. Powiedzmy, że tworzysz nową gałąź o nazwie testing. Zrobisz to za pomocą polecenia git branch:
$ git branch testingPolecenie to tworzy nowy wskaźnik na ten sam zestaw zmian, w którym aktualnie się znajdujesz (zobacz Rysunek 3-4).
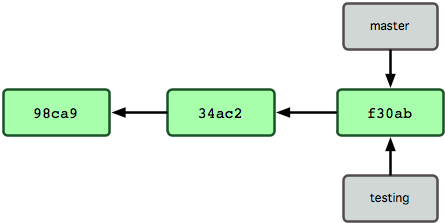
Figure 3-4. Wiele gałęzi wskazujących na dane zestawów zmian w historii.
Skąd Git wie, na której gałęzi się aktualnie znajdujesz? Utrzymuje on specjalny wskaźnik o nazwie HEAD. Istotnym jest, że bardzo różni się on od koncepcji HEADa znanej z innych systemów kontroli wersji, do jakich mogłeś się już przyzwyczaić, na przykład Subversion czy CVS. W Gicie jest to wskaźnik na lokalną gałąź, na której właśnie się znajdujesz. W tym wypadku, wciąż jesteś na gałęzi master. Polecenie git branch utworzyło jedynie nową gałąź, ale nie przełączyło cię na nią (porównaj z Rysunkiem 3-5).
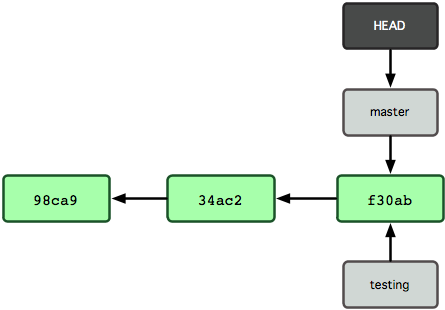
Figure 3-5. HEAD wskazuje na gałąź, na której się znajdujesz.
Aby przełączyć się na istniejącą gałąź, używasz polecenia git checkout. Przełączmy się zatem do nowo utworzonej gałęzi testing:
$ git checkout testingHEAD zostaje zmieniony tak, by wskazywać na gałąź testing (zobacz Rysunek 3-6).
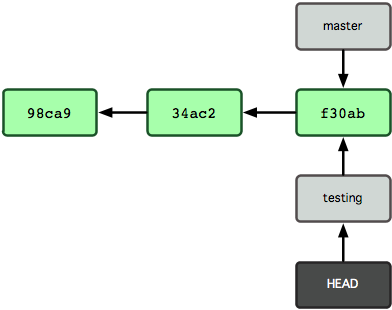
Figure 3-6. Po przełączaniu gałęzi, HEAD wskazuje inną gałąź.
Jakie ma to znaczenie? Zatwierdźmy nowe zmiany:
$ vim test.rb
$ git commit -a -m 'zmiana'Figure 3-7 ilustruje wynik operacji.
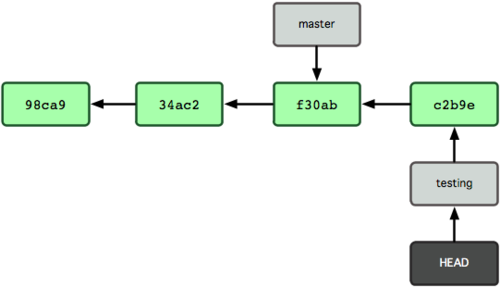
Figure 3-7. Gałąź wskazywana przez HEAD przesuwa się naprzód po każdym zatwierdzeniu zmian.
To interesujące, bo teraz twoja gałąź testing przesunęła się do przodu, jednak gałąź master ciągle wskazuje ten sam zestaw zmian, co w momencie użycia git checkout do zmiany aktywnej gałęzi. Przełączmy się zatem z powrotem na gałąź master:
$ git checkout masterFigure 3-8 pokazuje wynik.
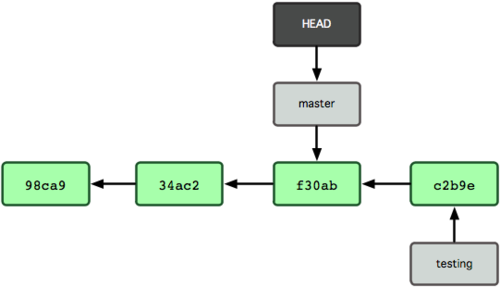
Figure 3-8. Po wykonaniu
checkout, HEAD przesuwa się na inną gałąź.
Polecenie dokonało dwóch rzeczy. Przesunęło wskaźnik HEAD z powrotem na gałąź master i przywróciło pliki w katalogu roboczym do stanu z migawki, na którą wskazuje master. Oznacza to również, że zmiany, które od tej pory wprowadzisz, będą rozwidlały się od starszej wersji projektu. W gruncie rzeczy cofa to tymczasowo pracę, jaką wykonałeś na gałęzi testing, byś mógł z dalszymi zmianami pójść w innym kierunku.
Wykonajmy teraz kilka zmian i zatwierdźmy je:
$ vim test.rb
$ git commit -a -m 'inna zmiana'Teraz historia twojego projektu została rozszczepiona (porównaj Rysunek 3-9). Stworzyłeś i przełączyłeś się na gałąź, wykonałeś na niej pracę, a następnie powróciłeś na gałąź główną i wykonałeś inną pracę. Oba zestawy zmian są od siebie odizolowane w odrębnych gałęziach: możesz przełączać się pomiędzy nimi oraz scalić je razem, kiedy będziesz na to gotowy. A wszystko to wykonałeś za pomocą dwóch prostych poleceń branch i checkout.
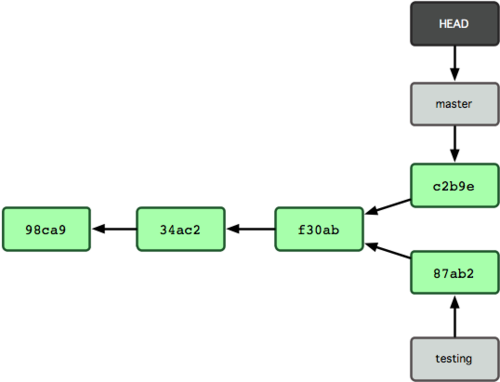
Figure 3-9. Rozwidlona historia gałęzi.
Ponieważ gałęzie w Gicie są tak naprawdę prostymi plikami, zawierającymi 40 znaków sumy kontrolnej SHA-1 zestawu zmian, na który wskazują, są one bardzo tanie w tworzeniu i usuwaniu. Stworzenie nowej gałęzi zajmuje dokładnie tyle czasu, co zapisanie 41 bajtów w pliku (40 znaków + znak nowej linii).
Wyraźnie kontrastuje to ze sposobem, w jaki gałęzie obsługuje większość narzędzi do kontroli wersji, gdzie z reguły w grę wchodzi kopiowanie wszystkich plików projektu do osobnego katalogu. Może to trwać kilkanaście sekund czy nawet minut, w zależności od rozmiarów projektu, podczas gdy w Gicie jest zawsze natychmiastowe. Co więcej, ponieważ wraz z każdym zestawem zmian zapamiętujemy jego rodziców, odnalezienie wspólnej bazy przed scaleniem jest automatycznie wykonywane za nas i samo w sobie jest niezwykle proste. Możliwości te pomagają zachęcić deweloperów do częstego tworzenia i wykorzystywania gałęzi.
Zobaczmy, dlaczego ty też powinieneś.